Lovable & SEO, le vrai bilan : ce que j'ai appris en construisant dot2.solutions
Un récit à la première personne où je heurte tous les murs SEO qu'une app Lovable peut rencontrer — et ce qui les corrige vraiment. Des canonicals dupliquées aux images OG cassées, voici l'audit honnête.

Chris
March 15, 2026 · 14 min read

Ask AI about this post



Un récit à la première personne où je heurte tous les murs SEO qu'une app Lovable peut rencontrer — et ce qui les corrige vraiment.
Je suis un développeur Lovable du top 1 %. J'ai livré plus de 1,1 million de lignes de code sur la plateforme. J'adore vraiment construire avec.
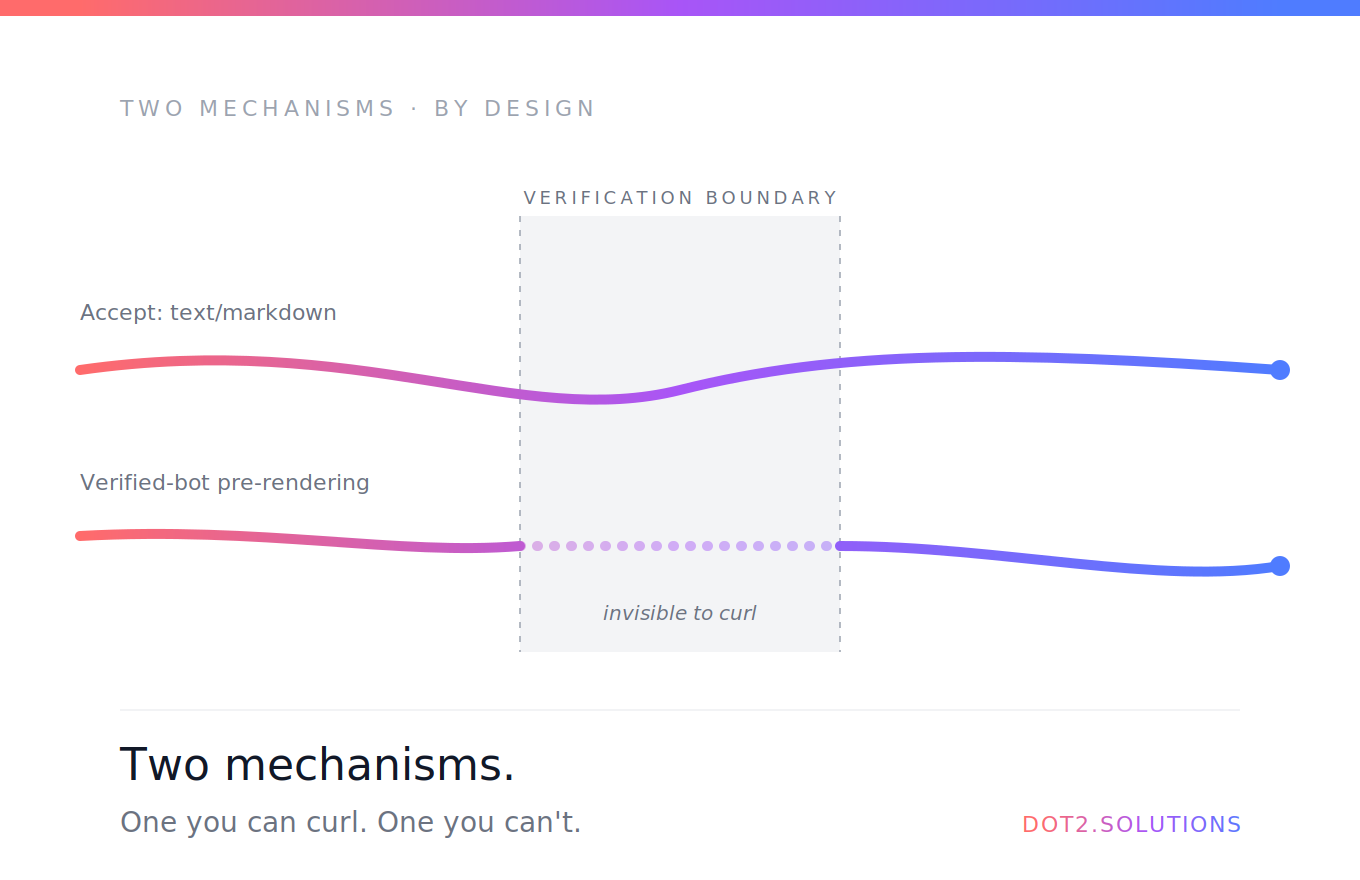
Et mon propre site a passé des mois avec 5 pages signalées dans Google Search Console comme « Dupliquée sans canonique sélectionnée par l'utilisateur ».
Cet article, c'est tout ce que j'ai appris en corrigeant ça — et en étant honnête sur ce que je n'arrivais pas à corriger.
D'abord, comprendre ce que Lovable construit vraiment
Lovable génère des applications React + Vite. Chaque site qu'il produit est donc une single-page application (SPA) rendue côté client (CSR).
En pratique : quand n'importe quel crawler — Google, LinkedIn, ChatGPT, Perplexity — interroge une URL de votre site, chaque page renvoie ceci :
<!DOCTYPE html>
<html>
<head>
<title>Titre de votre site</title>
<!-- les mêmes meta pour toutes les routes -->
</head>
<body>
<div id="root"></div>
</body>
</html>Le contenu réel — vos titres, votre texte, vos canonicals — n'existe qu'après le boot de React et l'exécution du JavaScript dans le navigateur. Pour les visiteurs humains, c'est transparent. Pour les crawlers, ça crée de vrais problèmes.
Ce n'est pas une critique de Lovable. C'est juste l'architecture. La comprendre est le prérequis pour tout le reste de cet article.
Les trois problèmes de crawler que ça crée
1. Le crawl en deux étapes de Google introduit des délais d'indexation
Google gère les sites CSR via un processus en deux étapes :
- Étape 1 : crawler le HTML initial (voit le shell vide)
- Étape 2 : revenir plus tard pour rendre le JavaScript et capter le vrai contenu
L'étape 2 est différée, déprioritisée, et n'est pas garantie rapidement. Pour une nouvelle page, ça peut vouloir dire des jours ou des semaines avant que votre contenu soit correctement indexé.
2. Les plateformes sociales et les crawlers IA ne voient rien
LinkedIn, Twitter/X, Facebook, ChatGPT, Perplexity — aucun n'exécute le JavaScript. Quand quelqu'un partage un lien vers votre article de blog sur LinkedIn, la plateforme va chercher l'URL pour générer un aperçu. Elle récupère votre shell vide et affiche soit des infos génériques, soit rien.
Ça compte plus que la plupart des builders Lovable ne le pensent. Vos balises Open Graph, soigneusement posées via react-helmet-async, sont totalement invisibles pour les crawlers sociaux.
3. Les canonicals via react-helmet-async arrivent trop tard
Mon setup SEO avait l'air correct. J'avais des composants SEOHead sur chaque page injectant titles, descriptions et canonicals uniques via react-helmet-async. Google Search Console signalait quand même 5 pages comme « Dupliquée sans canonique sélectionnée par l'utilisateur ».
Pourquoi ? Parce que ces canonicals sont injectées par JavaScript — donc le premier crawl de Google sur chaque page voit le même shell HTML avec le même titre de base d'index.html et aucun canonical spécifique à la page. Google voit 10 pages qui se ressemblent toutes et les signale comme doublons.
Ce que j'ai trouvé cassé sur mon propre site
Voici l'audit de dot2.solutions, honnête et sans filtre :
❌ Chemins relatifs sur les images OG dans index.html
<!-- Ce que j'avais — cassé pour les crawlers sociaux -->
<meta property="og:image" content="/lovable-uploads/image.png" />
<!-- Ce que ça devrait être -->
<meta property="og:image" content="https://dot2.solutions/lovable-uploads/image.png" />Les crawlers sociaux ne résolvent pas les chemins relatifs. Chaque partage de ma home générait un aperçu cassé. Un fix d'une ligne, un impact significatif.
❌ Mauvais ogImage par défaut dans le composant SEOHead
Mon composant SEOHead avait ce défaut :
ogImage = '/lovable-uploads/meet-fin3.webp'C'est une image d'article de blog — une photo liée à Fin — utilisée comme aperçu social pour toutes les pages qui ne définissaient pas explicitement une image. Ma page tarifs, ma page localisation, ma page contact partageaient toutes une image d'article Fin quand on les partageait sur LinkedIn.
❌ Duplication de schémas
J'avais des JSON-LD complets dans index.html — types Organization, LocalBusiness, Service. J'avais aussi un composant React StructuredData utilisé sur diverses pages. Sur toute page qui utilisait le composant avec les mêmes types de schéma, Googlebot voyait des schémas dupliqués.
Le fix : garder Organization et LocalBusiness dans index.html statique (ce sont des signaux d'identité sitewide que chaque crawler doit voir). Utiliser le composant uniquement pour les schémas spécifiques à la page — Article sur les billets de blog, Service sur les pages de service, FAQPage quand pertinent.
❌ Pas de canonical statique dans index.html
Mon index.html avait un commentaire disant que les canonicals étaient « surchargées par le composant SEOHead par page » — mais aucun fallback statique. Pour la home, et pour tout crawler qui n'exécute pas JS, il n'y avait aucun canonical dans le HTML statique.
Ajouter <link rel="canonical" href="https://dot2.solutions/" /> directement dans index.html est une mitigation simple.
❌ Directives bots IA manquantes dans robots.txt
Mon robots.txt gérait Googlebot et Bingbot mais rien pour les crawlers IA. Vu que le GEO (Generative Engine Optimization) est de plus en plus pertinent, c'était un oubli. Ajoutez des entrées explicites :
User-agent: GPTBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Claude-Web
Allow: /Les fix qui marchent vraiment dans Lovable
Tout est implémentable sans quitter la plateforme. Pour les instructions pas-à-pas et des prompts prêts à l'emploi, voir mon guide de setup SEO pour apps Lovable dans le centre d'aide.
- URLs absolues pour toutes les images OG — à la fois dans
index.htmlet comme défaut dans votre composant SEOHead. - Un ogImage par défaut brandé — utilisez votre vraie carte sociale comme fallback, pas une image de blog random.
- og:site_name et og:locale — ajoutez-les à SEOHead :
<meta property="og:site_name" content="nom de votre site" /> <meta property="og:locale" content="fr_CH" /> - Canonical statique dans index.html — au minimum pour la home.
- Directives crawlers IA dans robots.txt — Allow explicite pour GPTBot, PerplexityBot, Claude-Web.
- Séparation des scopes de schéma — schémas sitewide en statique dans
index.html, schémas spécifiques à la page via composant uniquement. - Injection de balises meta au build — c'est celle que j'ai vraiment shippée. Trois fichiers la font tourner :
scripts/prerender-meta.ts— un plugin Vite custom qui tourne au build, copiedist/index.htmldans des dossiers par route et injecte les bons<title>,<meta name="description">,<link rel="canonical">et balises OG/Twitter pour chaque routescripts/prerender-routes.ts— la config des métadonnées de route, auto-générée (voir plus bas)vite.config.ts— mis à jour pour inclure le plugin
Au build, les serveurs de Lovable génèrent des fichiers comme dist/intercom-expert/index.html et dist/blog/ai-agents/index.html — chacun avec des meta uniques cuites dans du HTML statique. Googlebot voit les canonicals immédiatement, sans JavaScript.
Le détail qui rend ça maintenable : un script scripts/generate-prerender-routes.ts lit tous les fichiers de données de billets de blog, extrait id, title et excerpt, et regénère automatiquement prerender-routes.ts. Il tourne en prebuild npm script — quand vous ajoutez un nouvel article, les routes restent synchro sans config manuelle.
Ça ne corrigera pas le body vide <div id="root"> — React le gère toujours côté client. Mais ça vise directement le problème « Dupliquée sans canonique sélectionnée par l'utilisateur » de Search Console.
Les fix qui demandent de sortir de Lovable
Soyons honnêtes sur le plafond.
Ce que l'injection meta au build NE corrige PAS : le body de votre page reste un <div id="root"> vide dans le HTML statique. Google doit toujours exécuter le JavaScript pour voir votre vrai contenu. Le délai du crawl en deux étapes reste. Pour un site à fort contenu où la recherche organique est le canal de croissance principal, c'est une vraie limite.
Ce que ça corrige : le « Dupliquée sans canonique » de Search Console — précisément parce que cette erreur porte sur l'absence de canonicals dans le HTML statique avant l'exécution du JS. Avec le plugin en place, chaque route clé obtient son propre fichier HTML avec le bon canonical cuit dedans. Je suis ça dans Search Console sur les 4–6 prochaines semaines pour confirmer que les pages signalées passent à indexées.
L'approche Cloudflare Worker + Prerender.io : j'ai regardé. Des retours terrain montrent une instabilité DNS au bout de quelques heures — vous finissez par revenir aux A records, ce qui contourne tout le setup. Pour un site de cabinet en production, un downtime intermittent est un pire problème qu'un indexage lent.
La route migration vers Framer : Framer résout élégamment le problème SSR pour les sites marketing purs. Mais si votre app Lovable a un backend Supabase, des flows d'auth, des portails clients ou toute fonctionnalité dynamique — Framer ne peut pas gérer. Vous finiriez avec deux codebases à maintenir.
💡 La recommandation honnête
Pour la plupart des builders Lovable, le bon move c'est :
- Implémenter tous les fix ci-dessus dans Lovable
- Déplacer votre blog vers Ghost si le SEO de contenu compte pour votre business
Ghost gère le SSR nativement, est conçu pour le contenu, et c'est sur le blog que le délai de crawl de Google fait le plus mal. Votre app reste sur Lovable, là où elle est à sa place.
Ce que Lovable fait bien côté SEO
Je ne veux pas que ça se lise comme purement critique — il y a beaucoup de choses que Lovable réussit :
- Support llms.txt — j'ai implémenté
llms.txtetllms-full.txtsur dot2.solutions. C'est vraiment en avance sur la plupart des sites pour le GEO et la visibilité auprès des crawlers IA. - Routing d'URL propre — React Router génère automatiquement des URLs propres et descriptives.
- HTML sémantique — Lovable génère de façon constante une structure
<main>,<nav>,<section>correcte. - Performance — les builds Vite sont rapides. Les Core Web Vitals tendent à être bons.
- Flexibilité — le pattern SEOHead, le composant StructuredData et la config
robots.txtdonnent un vrai contrôle dans les contraintes CSR.
Pour un cabinet comme le mien où l'acquisition vient principalement de LinkedIn, de la communauté Intercom et des recommandations — pas de la recherche organique — les limites CSR sont gérables. Pour un business content-first où le SEO est le canal de croissance principal, elles sont plus lourdes.
La checklist
Avant de shipper un site Lovable, vérifiez chacun des points (ou utilisez le guide complet de setup SEO pour les détails d'implémentation) :
La leçon plus large
Construire dans Lovable est rapide. Cette vitesse a un trade-off — vous shippez du CSR par défaut, et le CSR a des limites SEO connues qu'aucune config react-helmet-async ne résout entièrement.
Ce n'est pas une raison d'éviter Lovable. C'est une raison d'y aller avec des attentes justes, d'implémenter chaque mitigation disponible, et de prendre des décisions intentionnelles sur l'endroit où vit vraiment votre contenu.
Mon site rank toujours. Mes articles s'indexent. Les warnings Search Console s'améliorent. Mais je ne fais pas semblant que l'architecture est invisible.
Construis vite. Shippe souvent. Mais sache sur quoi tu construis.
Vous construisez avec Lovable et avez besoin d'un accompagnement expert ?
En tant que développeur Lovable du top 1 % avec 1,1M+ de lignes shippées, j'aide les équipes à atteindre des résultats production-ready — de l'architecture SEO aux intégrations complexes. Que vous ayez besoin d'un build complet ou d'une revue de code, parlons-en.
Voir nos services Lovable Expert →Christopher Boerger est le fondateur de dot2.solutions, un cabinet suisse d'automation du support IA spécialisé dans le déploiement d'Intercom Fin AI et l'architecture de bases de connaissances. Développeur Lovable du top 1 %.
Questions fréquentes
D'autres questions ?
Share this article
Building on Lovable? Let's Talk.
As a top-ranked Lovable expert, we help teams ship production-grade web apps — SEO, GEO, and SSR done right from day one.
No commitment required • Free 30-minute consultation • Expert guidance