La nouvelle fonctionnalité SEO de Lovable, testée de deux façons — et la partie que curl ne voit pas
J'ai failli écrire un autre article. Curl disait que la nouvelle suite de découvrabilité de Lovable ne faisait rien. Un second test — et un email au support de Lovable — a révélé deux mécanismes fonctionnant côte à côte, et pourquoi l'un d'eux est invisible par design.

Chris
May 19, 2026 · 7 min read
Ask AI about this post



J'ai failli écrire un autre article hier.
Lovable a livré une suite complète de découvrabilité — rendu côté serveur pour les nouvelles apps, pré-rendu pour les existantes, sortie markdown structurée pour les crawlers IA, intégration Semrush dans le chat builder, et une revue SEO à la demande avec des corrections en un clic. Le pitch principal : « vos apps sont découvrables dès leur publication ».
J'ai donc demandé à l'assistant IA intégré à Lovable comment la fonctionnalité marchait. Il a expliqué :
La couche d'hébergement de Lovable détecte les crawlers IA (GPTBot, PerplexityBot, ClaudeBot, etc.) via leur en-tête User-Agent. Quand l'un de ces bots demande une page de votre site publié, au lieu de renvoyer l'index.html normal (un shell SPA quasi vide qui a besoin de JavaScript pour s'afficher), l'edge sert une version Markdown pré-rendue de cette route.
Explication claire. Logique. Alors j'ai testé.
Le premier test : rien
Quatre requêtes curl contre dot2.solutions/about — trois User-Agents de bots IA et un navigateur en contrôle :
| User-Agent | HTTP | Content-Type | Octets |
|---|---|---|---|
| Navigateur classique | 200 | text/html | 14052 |
| GPTBot | 200 | text/html | 14052 |
| ClaudeBot | 200 | text/html | 14052 |
| PerplexityBot | 200 | text/html | 14052 |
Réponses identiques. Même status, même content-type, même nombre d'octets, même shell SPA. Pas de variante markdown. Pas de contenu différent pour les bots.
J'ai failli écrire cet article. « Lovable l'a annoncé, j'ai testé immédiatement, rien de différent sur le fil. » Données propres, conclusion décevante. Le posture sceptique facile.
Puis j'ai fait un test de plus.
Le second test : un autre type de négociation
L'annonce utilisait deux expressions distinctes : « pré-rendu pour les apps existantes » et « sortie markdown structurée ». Deux fonctionnalités différentes. La plupart des outils de découvrabilité routent par User-Agent. Mais « sortie markdown structurée » ressemblait davantage à la négociation de contenu HTTP — l'approche standard où le client indique au serveur le format voulu, et le serveur choisit la meilleure réponse.
J'ai donc demandé du markdown au serveur directement :
curl -H "Accept: text/markdown" https://dot2.solutions/about -iRéponse :
HTTP/2 200
content-type: text/markdown; charset=utf-8
content-length: 7693
vary: AcceptCorps markdown propre. Moitié de la taille de la réponse HTML. Titres, liens, paragraphes — du contenu pur, sans chrome, sans scripts.
L'en-tête vary: Accept est révélateur. C'est le serveur disant explicitement aux caches et aux clients : « je sers un contenu différent selon l'en-tête Accept que vous envoyez ». Négociation de contenu HTTP standard, exactement comme le web a été conçu pour cela.
Donc un chemin fonctionnait. Le chemin User-Agent, non. Même site, même edge — résultat différent. C'est la question à laquelle je ne pouvais pas répondre avec curl seul.
La question pour laquelle j'ai dû envoyer un email
Si la fonctionnalité de pré-rendu était réelle et déployée, pourquoi les quatre User-Agents de crawlers renvoyaient-ils des shells SPA identiques ? Soit la fonctionnalité n'était pas active, soit mon test était faux.
J'ai demandé directement à Lovable. Le support Lovable a répondu en un jour avec la réponse :
Les tests curl que vous faites renverront toujours le shell SPA, même si tout fonctionne parfaitement. Le pré-rendu sur Lovable n'est servi qu'aux bots que Cloudflare a vérifiés (le vrai Googlebot, le vrai GPTBot, etc., identifiés par IP et signature, pas seulement par user-agent). Quand vous définissez une chaîne user-agent dans curl, vous imitez un bot mais la requête provient toujours de votre propre machine, donc Cloudflare ne la classe pas comme un bot vérifié et c'est le shell SPA qui est renvoyé. C'est intentionnel, pour empêcher les abus.
La boucle est bouclée. La fonctionnalité marche. Curl ne peut tout simplement pas la déclencher — et n'est pas censé pouvoir.
Ce qui se passe réellement
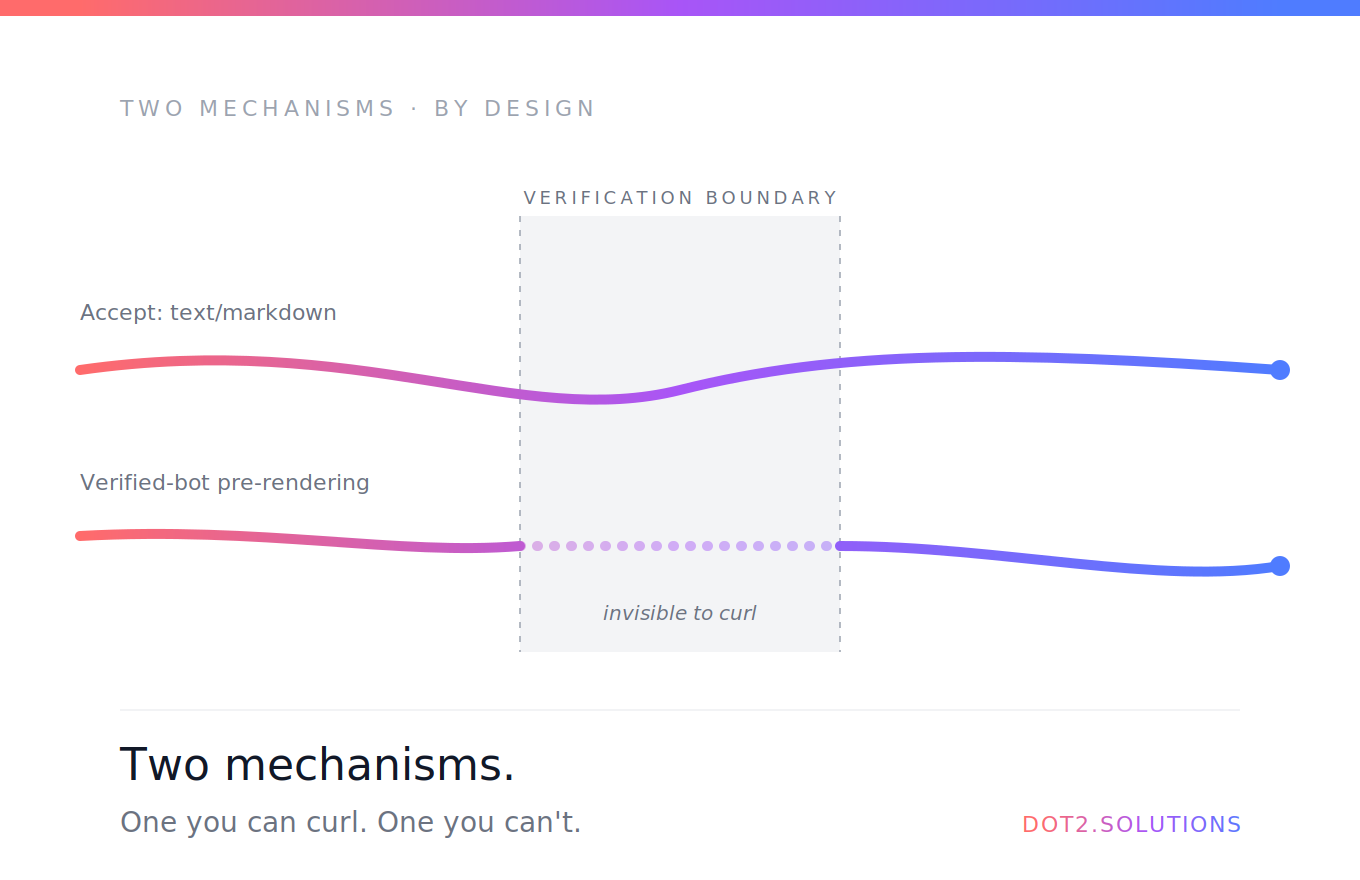
Deux mécanismes tournent côte à côte, chacun résolvant un problème différent.
Mécanisme 1 : pré-rendu pour bots vérifiés. Quand un vrai crawler vérifié par Cloudflare touche un site Lovable — Googlebot, GPTBot, ClaudeBot, identifié par IP plus signature cryptographique plutôt que par la simple chaîne UA — l'edge sert du HTML pré-rendu. Usurper le User-Agent ne trompe pas la vérification Cloudflare, c'est tout l'intérêt. Vous pouvez utiliser n'importe quel UA dans curl ; Cloudflare sait que votre requête ne provient pas de l'infrastructure d'OpenAI ou d'Anthropic. Anti-abus par design.
Mécanisme 2 : négociation de contenu via Accept. Tout client — y compris curl depuis votre laptop — qui demande explicitement text/markdown via l'en-tête Accept reçoit du markdown propre. Aucune vérification nécessaire. C'est le chemin universel, toujours actif.
Ensemble, ils couvrent tout le paysage du trafic IA :
- Les crawlers d'indexation qui s'identifient cryptographiquement obtiennent du HTML pré-rendu, rapidement.
- Les outils agentiques et les fetchers à la demande qui demandent du markdown obtiennent du markdown, peu importe qui ils sont.
- Tous les autres obtiennent le shell SPA normal.
C'est une architecture intelligente. Anti-spoofing là où le spoofing compte, négociation de contenu ouverte là où ça n'a pas d'importance.
Réalité pratique
Le support Lovable a souligné la limite que j'aurais sinon manquée : très peu d'assistants IA demandent du markdown aujourd'hui en pratique, donc même si tout est correctement câblé, vous ne verriez pas beaucoup de trafic réel passer par là pour l'instant.
C'est juste. Le chemin Accept est compatible avec l'avenir — il est conçu pour les outils IA qui arrivent l'an prochain, pas pour le paysage des bots d'aujourd'hui. La plupart des crawlers IA actuels envoient Accept: text/html, */* et recevront du HTML.
Mais l'architecture est positionnée là où le palet va. La lecture d'URL à la demande de ChatGPT, le fetch d'URL de Claude, le mode recherche de Perplexity et les frameworks agentiques émergents demandent de plus en plus du markdown parce que c'est nettement plus facile à parser pour un LLM que de la soupe HTML. Le pré-rendu pour bots vérifiés couvre les crawlers d'indexation maintenant. Le chemin Accept couvre ce qui vient ensuite. L'implémentation est bonne pour les deux échéances.
Méthodologie de test, avec ses limites
Si vous voulez vérifier la découvrabilité sur votre propre projet Lovable :
# Ce que les navigateurs (et la plupart des crawlers actuels) obtiennent
curl -i https://votre-domaine.com/une-page | head -10
# Ce qu'un outil IA demandant du markdown obtient
curl -H "Accept: text/markdown" https://votre-domaine.com/une-page -i | head -10Pour la seconde réponse, cherchez content-type: text/markdown et un en-tête vary: Accept. Si vous voyez les deux, le chemin markdown est actif sur votre projet.
Pour le pré-rendu pour bots vérifiés, vous ne pouvez pas le tester avec curl par design. Vous pouvez le vérifier indirectement via l'outil d'inspection d'URL de Google Search Console (qui vous montre ce que le vrai Googlebot a vu lors de son dernier crawl) et via des fonctionnalités d'audit similaires dans d'autres outils de recherche IA à mesure qu'elles deviennent disponibles. L'architecture repose sur la vérification de bots de Cloudflare, qui est bien documentée et fiable.
Le pattern
Quand les plateformes livrent des fonctionnalités à plusieurs mécanismes, les assistants IA intégrés qui les expliquent ont tendance à décrire un mécanisme proprement et à manquer les autres. Ce n'est pas de la malveillance. C'est le coût d'avoir des assistants IA qui expliquent les fonctionnalités livrées plus vite que la documentation ne peut suivre.
La solution n'est pas de se méfier de la plateforme. C'est de tester ce qu'on peut avec curl, de savoir ce que curl ne peut pas montrer, et d'envoyer un email aux ingénieurs quand on atteint la limite.
Pour les builders qui livrent sur Lovable : les nouvelles fonctionnalités de découvrabilité sont réelles, techniquement excellentes et actives sur les projets existants — y compris le mien, même sur le template SPA pré-avril. Testez le chemin Accept avec curl. Faites confiance au chemin pour bots vérifiés car c'est pour ça qu'il est conçu. Les deux font du vrai travail.
Pour Lovable : l'implémentation est excellente. L'explication par l'assistant IA intégré pourrait couvrir les deux mécanismes — ça m'aurait épargné quelques tours de curl et un email. Mais je suis content d'avoir envoyé l'email quand même. C'est comme ça qu'on apprend comment les choses fonctionnent vraiment.
Dans la suite de l'article SSR de la semaine dernière — ceci est la deuxième partie de ce qui devient une série sur l'histoire de la découvrabilité chez Lovable. Prochain épisode : un regard de plus près sur l'intégration Semrush et ce que ces corrections SEO en un clic font réellement en pratique.
Questions fréquentes
D'autres questions ?
Share this article
Building on Lovable? Let's Talk.
As a top-ranked Lovable expert, we help teams ship production-grade web apps — SEO, GEO, and SSR done right from day one.
No commitment required • Free 30-minute consultation • Expert guidance
