Eoghan a dit « Fin pour les dentistes ». Il a raison. Voici ce que ça veut vraiment dire.
Intercom a lancé la Fin API Platform avec des contrats à 250 K$/an et Apex — un LLM spécialisé qui surpasse GPT-5.4 et Opus 4.5. Mais la vraie histoire, ce n'est pas le modèle. C'est l'écart de mise en œuvre verticale.

Chris
April 8, 2026 · 12 min read

Ask AI about this post



La semaine dernière, Intercom a lancé la Fin API Platform. Les contrats démarrent à 250 K$/an. Apex — leur nouveau LLM spécialisé pour le service client — surpasse, selon les benchmarks, GPT-5.4 et Opus 4.5 sur le taux de résolution, le taux d'hallucination et la latence.
C'est une annonce importante. Et la plupart des analyses vont se focaliser sur les benchmarks du modèle.
Je veux plutôt me focaliser sur une phrase du post d'Eoghan McCabe.
« Nous n'allons jamais construire pour ces verticales spécifiques. »
Voici la citation complète, glissée vers la fin de son annonce :
« Fin pour les dentistes ? Pourquoi pas. Fin pour les concessions auto ? Bien sûr. Nous n'allons jamais construire pour ces verticales spécifiques, mais nous adorerions que quelqu'un d'autre le fasse. »
Relisez ça deux fois.
Le CEO d'Intercom — qui annonce ce qu'il qualifie de meilleur modèle de support client au monde — dit ouvertement : le travail d'implémentation verticale n'est pas le nôtre.
Ce n'est pas une phrase jetée. C'est une frontière stratégique. Et elle a des implications réelles pour quiconque déploie Fin chez des clients PME.
Ce que la Plateforme API ouvre réellement
La Fin API Platform donne aux builders accès à quatre couches de modèles :
- Fin Apex 1.0 — le modèle génératif qui produit les réponses finales
- Fin RAG API — le pipeline complet de retrieval-augmented generation
- Fin Retrieval API — un modèle de retrieval sur mesure optimisé pour le support client
- Fin Reranker API — scoring de pertinence du contenu remonté
C'est une infrastructure réellement puissante. Les benchmarks d'Apex sont sérieux : +2,8 % de taux de résolution par rapport aux modèles frontière, 65 % d'hallucinations en moins que Sonnet 4.6, 0,6 seconde plus rapide sur le temps au premier token.
L'impact réel suit : Intercom a rapporté qu'un gros client gaming a vu son taux de résolution passer du jour au lendemain de 68 % à 75 % après le rollout d'Apex — une baisse de 22 % des conversations non résolues, et la plus grosse amélioration en une seule étape depuis le lancement de Fin.
Mais le plancher annuel de 250 K$ indique clairement à qui s'adresse cette plateforme : entreprises, startups qui construisent des agents verticaux, et concurrents de la plateforme Intercom qui veulent licencier les modèles.
Pour la grande majorité des PME, ce n'est pas un terrain d'accès direct. Et c'est très bien — parce que l'API n'est pas là où se trouve l'écart de valeur pour elles, de toute façon.
La couche connaissance reste le fossé défensif
Voici ce que chaque implémentation IA que j'ai pilotée a confirmé, et ce que le Blueprint AI Agent d'Intercom explicite :
Le taux de résolution n'est pas, en premier lieu, un problème de modèle. C'est un problème de contenu.
Le Blueprint le dit clairement : « Les AI Agents ne valent que par leurs inputs. » Et la remarque d'Eoghan sur les dentistes et les concessions auto pointe exactement la même chose : vous pouvez avoir le meilleur modèle du monde, si l'architecture de connaissances en dessous n'est pas construite autour du fonctionnement de votre verticale, vous n'atteindrez pas de taux de résolution significatifs.
Apex sur une base de connaissances générique et mal structurée sous-performera. Une instance Fin bien configurée sur une couche de contenu propre et calibrée pour la verticale la surclassera systématiquement.
C'est l'écart que la plateforme API ne comble pas. Et c'est l'écart qui compte pour les déploiements PME. Si vous construisez ou auditez votre couche de contenu, notre guide sur les bases de connaissances pour le support IA en couvre les principes fondamentaux.
Ce que « contenu avant configuration » veut dire concrètement
Quand on parle de contenu avant configuration chez dot2.solutions, on parle de quelque chose de précis :
Avant de toucher au moindre réglage Intercom, vous devez savoir :
- Quelles questions vos clients posent réellement (pas celles que vous pensez qu'ils posent)
- Lesquelles sont à fort volume et faible complexité — votre voie rapide vers la résolution
- Où votre contenu existant est faux, obsolète ou totalement absent
- Comment vos SOPs se mappent au format Procedures de Fin
- Quelle logique conditionnelle exigent réellement vos workflows les plus complexes
Ça, c'est l'architecture de connaissances. Ce n'est pas glamour. Ça ne fait pas de belles slides de benchmark. Mais c'est le travail qui détermine si vous atteignez 65 % de résolution ou 30 %.
Intercom a construit le meilleur modèle pour ça. Ils ont aussi construit un outillage solide autour — Guidance, Procedures, Simulations, Topics Explorer. La plateforme est réellement excellente. Et avec le lancement récent de Monitors, la couche d'observabilité est maintenant complète aussi — ce qui veut dire que vous pouvez enfin mesurer si les réponses de Fin sont à votre niveau d'exigence, pas seulement si elles résolvent des conversations.
Ce qu'ils ne font pas — de leur propre aveu — c'est le travail vertical sur le contenu. Le travail de fond sur la façon dont une fiduciaire suisse parle TVA à ses clients, ou dont une SaaS genevoise gère les conversations de churn en français. Ça, c'est de l'implémentation. C'est du travail de praticien.
L'opportunité que ça crée
La Fin API Platform va générer une vague de nouveaux builders d'agents verticaux. Eoghan les invite explicitement. Certains seront des startups bien financées. D'autres, des cabinets de conseil qui rebrandent du jour au lendemain.
La plupart vont démarrer par la couche modèle, parce que c'est ce qui est nouveau et excitant.
Ceux qui réussiront finiront par apprendre ce que tout implémenteur Fin expérimenté sait déjà : le modèle, c'est la partie facile. Ce qui demande du temps, du jugement et une connaissance métier, c'est l'architecture de contenu en dessous.
C'est l'opportunité asymétrique pour les partenaires d'implémentation qui ont déjà fait ce travail — qui ont construit les frameworks, mené les audits de connaissances, et appris quelles structures de contenu Fin résout réellement vs lesquelles il contourne.
La couche modèle s'ouvre. La couche connaissance reste le fossé défensif.
Pour une vision plus large de comment les stratégies de support IA proactif s'empilent sur cette fondation, voir notre article sur le support IA proactif en 2026.
Une note sur les benchmarks
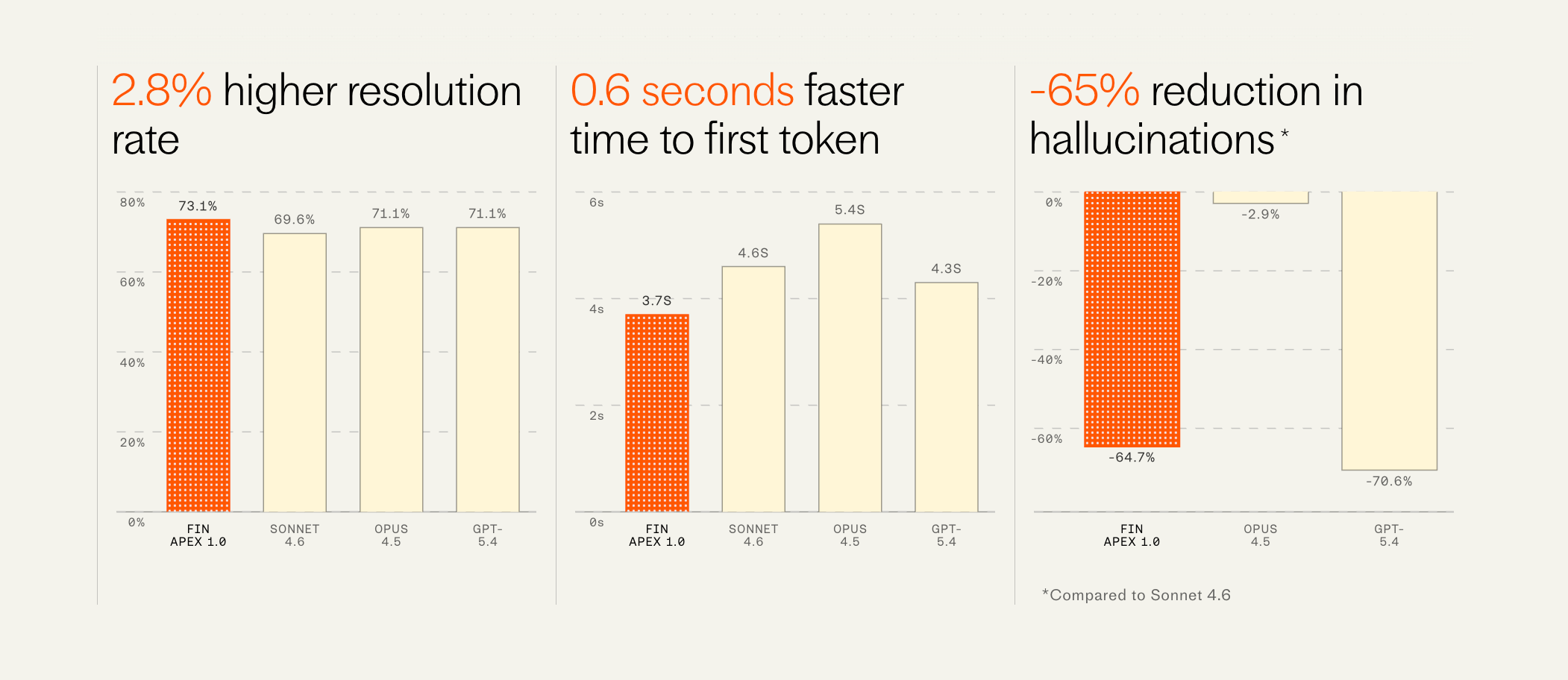
Les chiffres d'Apex méritent qu'on s'y attarde. Se comparer favorablement à GPT-5.4 et Opus 4.5 sur un benchmark spécifique au support client n'est pas une affirmation triviale. Intercom a une équipe IA de 60 personnes, dix ans de données de support client, et des années de signal de production issu de millions de conversations Fin par semaine.
Voir des modèles verticaux spécialisés surpasser des modèles frontière généralistes est exactement ce à quoi on s'attend dans les verticales IA matures. Médical, juridique, financier et support client vont tous dans cette direction. La suite de modèles Fin est en avance sur là où je l'attendais.
Le Fin Escalation Router à lui seul — >98 % de précision sur les décisions de handoff, 0,5 s plus rapide que le routing basé LLM — montre combien de valeur composée se trouve dans l'architecture des sous-agents spécialisés plutôt que dans le LLM en titre.
Au-delà de la performance brute du modèle, la suite complète d'Intercom inclut maintenant sept modèles spécialisés : Apex 1.0, Retrieval, Reranker, Issue Summarizer, Feedback Parser, Language Detector et l'Escalation Router. Chacun est conçu et fine-tuné pour une étape précise du pipeline de support — une architecture composite difficile à répliquer avec des modèles frontière génériques seuls.
Ce que ça veut dire pour nos clients
Pour les PME suisses qui déploient Fin via dot2.solutions, rien ne change dans notre approche de fond. La plateforme sur laquelle vous tournez vient juste de progresser de façon significative. Si la Plateforme API custom a un ticket d'entrée d'un quart de million, Intercom intègre le modèle Apex directement dans le produit Fin standard. Ça veut dire qu'Apex est le modèle derrière votre instance Fin dorénavant.
Ce que ça améliore : précision de résolution, taux d'hallucination, latence de réponse, et décisions d'escalade.
Ce que ça ne change pas : la qualité de votre base de connaissances, la structure de vos Procedures, la clarté de votre Guidance. Ces leviers restent les principaux pour faire progresser le taux de résolution — et c'est là qu'on passe le plus de temps.
Si vous utilisez déjà Fin, c'est le bon moment pour vérifier si votre couche contenu suit le rythme des progrès du modèle. Les stratégies sur les questions rapides et la résolution qu'on a décrites sont un bon point de départ pratique.
Si vous ne tournez pas encore sous Fin et que cette annonce vous intrigue : le meilleur point de départ reste un audit de connaissances, pas une évaluation d'outil.
Contenu avant configuration. C'est là que se gagne ou se perd votre taux de résolution — peu importe à quel point le modèle s'améliore. Si vous êtes prêt à arrêter de bricoler les réglages et à construire une couche de connaissances qui résout réellement les tickets, parlons d'un audit de connaissances.
Questions fréquentes
D'autres questions ?
Share this article
Need Help with Intercom & Fin?
As an Intercom Silver Partner, we specialise in Fin deployment, knowledge base architecture, and AI support automation for Swiss SMEs.
No commitment required • Free 30-minute consultation • Expert guidance


