Il reality check SEO di Lovable: cosa ho imparato costruendo dot2.solutions
Un racconto in prima persona dove sbatto contro ogni muro SEO che un'app Lovable può incontrare — e cosa li sistema davvero. Da canonical duplicate a OG image rotte, ecco l'audit onesto.

Chris
March 15, 2026 · 14 min read

Ask AI about this post



Un racconto in prima persona dove sbatto contro ogni muro SEO che un'app Lovable può incontrare — e cosa li sistema davvero.
Sono uno sviluppatore Lovable del top 1%. Ho spedito oltre 1,1 milioni di righe di codice sulla piattaforma. Mi piace davvero costruirci.
E il mio sito personale ha passato mesi con 5 pagine segnalate in Google Search Console come «Duplicata senza canonical selezionato dall'utente».
Questo articolo è tutto ciò che ho imparato sistemandolo — e l'onestà su ciò che non sono riuscito a sistemare.
Prima, capire cosa costruisce davvero Lovable
Lovable genera applicazioni React + Vite. Significa che ogni sito che produce è una single-page application (SPA) renderizzata lato client (CSR).
In pratica: quando un qualsiasi crawler — Google, LinkedIn, ChatGPT, Perplexity — interroga un URL del tuo sito, ogni pagina restituisce questo:
<!DOCTYPE html>
<html>
<head>
<title>Titolo del tuo sito</title>
<!-- gli stessi meta tag per ogni route -->
</head>
<body>
<div id="root"></div>
</body>
</html>Il contenuto vero — titoli, testi, tag canonical — esiste solo dopo che React parte e il JavaScript gira nel browser. Per i visitatori umani è invisibile. Per i crawler crea problemi veri.
Non è una critica a Lovable. È solo l'architettura. Capirla è il prerequisito per tutto il resto dell'articolo.
I tre problemi di crawler che questo crea
1. Il crawl in due fasi di Google introduce ritardi di indicizzazione
Google gestisce i siti CSR in due fasi:
- Fase 1: crawl dell'HTML iniziale (vede lo shell vuoto)
- Fase 2: ritorna più tardi per renderizzare il JavaScript e catturare il contenuto reale
La Fase 2 è ritardata, depriorizzata e non garantita rapidamente. Per una pagina nuova può voler dire giorni o settimane prima che il contenuto sia indicizzato correttamente.
2. Le piattaforme social e i crawler AI non vedono nulla
LinkedIn, Twitter/X, Facebook, ChatGPT, Perplexity — nessuno esegue JavaScript. Quando qualcuno condivide un link al tuo post su LinkedIn, la piattaforma chiama l'URL per generare l'anteprima, ottiene lo shell vuoto e mostra informazioni generiche o nulla.
Conta più di quanto la maggior parte dei builder Lovable pensi. I tag Open Graph, impostati con cura via react-helmet-async, sono completamente invisibili ai crawler social.
3. I canonical di react-helmet-async arrivano troppo tardi
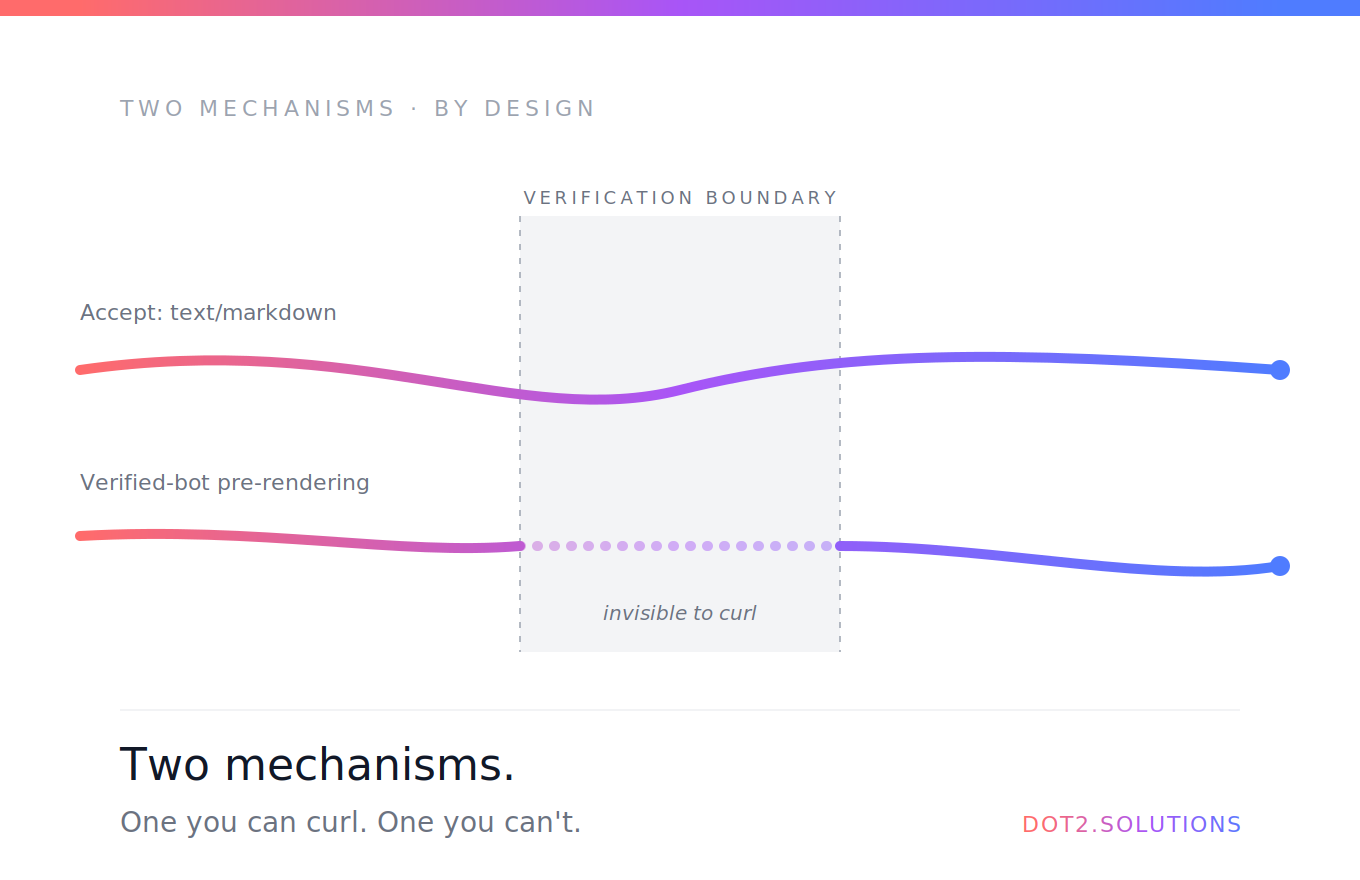
Il mio setup SEO sembrava corretto. Avevo componenti SEOHead su ogni pagina che iniettavano title, description e canonical unici via react-helmet-async. Google Search Console comunque segnalava 5 pagine come «Duplicata senza canonical selezionato dall'utente».
Perché? Perché quei canonical sono iniettati da JavaScript — quindi il primo crawl di Google su ogni pagina vede lo stesso shell HTML, lo stesso title di base dell'index.html e nessun canonical specifico per pagina. Google vede 10 pagine identiche e le marca come duplicate.
Cosa ho trovato rotto sul mio sito
Ecco l'audit di dot2.solutions, onesto e senza filtri:
❌ Path relativi sulle immagini OG in index.html
<!-- Quello che avevo — rotto per i crawler social -->
<meta property="og:image" content="/lovable-uploads/image.png" />
<!-- Quello che dovrebbe essere -->
<meta property="og:image" content="https://dot2.solutions/lovable-uploads/image.png" />I crawler social non risolvono i path relativi. Ogni share della mia home generava un'anteprima rotta. Fix di una riga, impatto significativo.
❌ ogImage di default sbagliato nel componente SEOHead
Il mio componente SEOHead aveva questo default:
ogImage = '/lovable-uploads/meet-fin3.webp'È un'immagine di un post del blog — una foto legata a Fin — usata come anteprima social per ogni pagina che non ne impostava una esplicita. Pagina prezzi, pagina localizzazione, pagina contatti: tutte condividevano un'immagine di articolo Fin su LinkedIn.
❌ Duplicazione di schema
Avevo JSON-LD completi in index.html — tipi Organization, LocalBusiness, Service. Avevo anche un componente React StructuredData usato su varie pagine. Su ogni pagina che usava il componente con gli stessi tipi di schema, Googlebot vedeva schema duplicati.
Il fix: tenere Organization e LocalBusiness nell'index.html statica (sono segnali di identità sitewide che ogni crawler deve vedere). Usare il componente solo per schema specifici di pagina — Article sui post, Service sulle pagine servizio, FAQPage dove pertinente.
❌ Nessun canonical statico in index.html
La mia index.html aveva un commento che diceva che i canonical venivano «sovrascritti dal componente SEOHead per pagina» — ma nessun fallback statico. Per la home, e per ogni crawler che non esegue JS, non c'era alcun canonical nell'HTML statico.
Aggiungere <link rel="canonical" href="https://dot2.solutions/" /> direttamente nell'index.html è una mitigazione semplice.
❌ Direttive bot AI mancanti in robots.txt
La mia robots.txt gestiva Googlebot e Bingbot ma non aveva nulla per i crawler AI. Visto che il GEO (Generative Engine Optimization) è sempre più rilevante, era una svista. Aggiungi voci esplicite:
User-agent: GPTBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Claude-Web
Allow: /I fix che funzionano davvero dentro Lovable
Tutti implementabili senza lasciare la piattaforma. Per istruzioni passo passo e prompt pronti all'uso, vedi la mia guida di setup SEO per app Lovable nel centro assistenza.
- URL assoluti per tutte le immagini OG — sia in
index.htmlsia come fallback di default nel componente SEOHead. - Un ogImage di default brandizzato — usa la tua vera social card come fallback, non un'immagine di blog a caso.
- og:site_name e og:locale — aggiungili in SEOHead:
<meta property="og:site_name" content="nome del tuo sito" /> <meta property="og:locale" content="it_CH" /> - Canonical statico in index.html — almeno per la home.
- Direttive crawler AI in robots.txt — Allow esplicito per GPTBot, PerplexityBot, Claude-Web.
- Separazione degli scope di schema — schema sitewide statici in
index.html, schema specifici di pagina solo via componente. - Iniezione di meta tag al build — è quella che ho davvero spedito. Tre file la fanno funzionare:
scripts/prerender-meta.ts— un plugin Vite custom che gira al build, copiadist/index.htmlin cartelle per route e inietta i corretti<title>,<meta name="description">,<link rel="canonical">e tag OG/Twitter per ogni routescripts/prerender-routes.ts— la config dei metadati di route, auto-generata (vedi sotto)vite.config.ts— aggiornato per includere il plugin
Al build, i server di Lovable generano file come dist/intercom-expert/index.html e dist/blog/ai-agents/index.html — ciascuno con meta tag unici cotti nell'HTML statico. Googlebot vede i canonical immediatamente, senza JavaScript.
Il dettaglio che lo rende manutenibile: uno script scripts/generate-prerender-routes.ts legge tutti i file dati dei post, estrae id, title ed excerpt e rigenera prerender-routes.ts. Gira come prebuild npm script — quando aggiungi un nuovo post, le route restano allineate senza config manuale.
Non sistemerà il body vuoto <div id="root"> — React continua a gestirlo lato client. Ma colpisce direttamente il problema «Duplicata senza canonical selezionato dall'utente» di Search Console.
I fix che richiedono di uscire da Lovable
Siamo onesti sul soffitto.
Cosa l'iniezione di meta al build NON sistema: il body della pagina resta un <div id="root"> vuoto nell'HTML statico. Google deve comunque eseguire JavaScript per vedere il contenuto reale. Il ritardo del crawl in due fasi rimane. Per un sito a forte contenuto dove la ricerca organica è il canale di crescita primario, è un limite vero.
Cosa sistema: il «Duplicata senza canonical» di Search Console — proprio perché quell'errore riguarda il fatto che Google non vede canonical nell'HTML statico prima dell'esecuzione del JS. Con il plugin in place, ogni route chiave ottiene un proprio file HTML con il canonical corretto inserito. Sto tracciando la cosa in Search Console nelle prossime 4–6 settimane per confermare che le pagine segnalate passino a indicizzate.
L'approccio Cloudflare Worker + Prerender.io: l'ho valutato. Report dal campo mostrano instabilità DNS dopo poche ore — finisci col tornare ai record A, bypassando l'intero setup. Per un sito di consulenza in produzione, un downtime intermittente è un problema peggiore di un'indicizzazione lenta.
La strada della migrazione a Framer: Framer risolve elegantemente il problema SSR per siti puramente marketing. Ma se la tua app Lovable ha backend Supabase, flussi di auth, portali clienti o qualsiasi funzionalità dinamica — Framer non può gestirla. Finiresti con due codebase da mantenere.
💡 La raccomandazione onesta
Per la maggior parte dei builder Lovable la mossa giusta è:
- Implementare tutti i fix sopra dentro Lovable
- Spostare il blog su Ghost se il SEO di contenuto conta per il tuo business
Ghost gestisce SSR nativamente, è costruito per il contenuto, e il blog è dove il ritardo di crawl di Google fa più male. La tua app resta su Lovable, dove le compete.
Cosa fa bene Lovable per il SEO
Non voglio che si legga come solo critico — c'è tanto che Lovable fa bene:
- Supporto llms.txt — ho implementato
llms.txtellms-full.txtsu dot2.solutions. È davvero in anticipo rispetto alla maggior parte dei siti per GEO e visibilità ai crawler AI. - Routing di URL puliti — React Router genera URL puliti e descrittivi automaticamente.
- HTML semantico — Lovable genera coerentemente strutture
<main>,<nav>,<section>corrette. - Performance — le build Vite sono veloci. I Core Web Vitals tendono a essere buoni.
- Flessibilità — il pattern SEOHead, il componente StructuredData e la config
robots.txtti danno controllo reale entro i vincoli CSR.
Per una consulenza come la mia, dove l'acquisizione arriva principalmente da LinkedIn, dalla community Intercom e dai referral — non dalla ricerca organica — i limiti del CSR sono gestibili. Per un business content-first dove il SEO è il canale di crescita primario, sono più pesanti.
La checklist
Prima di spedire un sito Lovable, verifica ognuno di questi punti (o usa la guida completa di setup SEO per i dettagli di implementazione):
La lezione più ampia
Costruire in Lovable è veloce. Quella velocità ha un trade-off — di default spedisci CSR, e il CSR ha limiti SEO noti che nessuna configurazione di react-helmet-async risolve del tutto.
Non è una ragione per evitare Lovable. È una ragione per entrarci con aspettative giuste, implementare ogni mitigazione disponibile e fare scelte intenzionali su dove vive davvero il tuo contenuto.
Il mio sito continua a posizionarsi. I miei post vengono indicizzati. I warning di Search Console stanno migliorando. Ma non finto che l'architettura sia invisibile.
Costruisci veloce. Spedisci spesso. Ma sappi su cosa costruisci.
Costruisci con Lovable e vuoi una guida esperta?
Come sviluppatore Lovable del top 1% con 1,1M+ di righe spedite, aiuto i team ad arrivare a risultati production-ready — dall'architettura SEO alle integrazioni complesse. Che ti serva una build completa o una code review, parliamone.
Scopri i nostri servizi Lovable Expert →Christopher Boerger è il fondatore di dot2.solutions, una consulenza svizzera di automazione del supporto AI specializzata nel deployment di Intercom Fin AI e nell'architettura di knowledge base. Sviluppatore Lovable del top 1%.
Domande frequenti
Hai altre domande?
Share this article
Building on Lovable? Let's Talk.
As a top-ranked Lovable expert, we help teams ship production-grade web apps — SEO, GEO, and SSR done right from day one.
No commitment required • Free 30-minute consultation • Expert guidance