La nuova funzione SEO di Lovable, testata in due modi — e la parte che curl non vede
Stavo per scrivere un articolo diverso. Curl diceva che la nuova suite di discoverability di Lovable non faceva nulla. Un secondo test — e un'email al supporto Lovable — ha mostrato due meccanismi che funzionano in parallelo, e perché uno di essi è invisibile by design.

Chris
May 19, 2026 · 7 min read
Ask AI about this post



Ieri stavo per scrivere un articolo diverso.
Lovable ha rilasciato una suite completa di discoverability — server-side rendering per le nuove app, pre-rendering per quelle esistenti, output markdown strutturato per i crawler AI, integrazione Semrush nel builder chat e una revisione SEO on-demand con fix in un clic. Il pitch: « le tue app sono trovabili dal momento in cui le pubblichi ».
Ho quindi chiesto all'assistente AI integrato in Lovable come funziona la feature. Ha spiegato:
Il livello di hosting di Lovable rileva i crawler AI (GPTBot, PerplexityBot, ClaudeBot, ecc.) tramite l'header User-Agent. Quando uno di questi bot richiede una pagina del tuo sito pubblicato, invece di restituire la normale index.html (una shell SPA quasi vuota che necessita JavaScript per essere renderizzata), l'edge serve una versione Markdown pre-renderizzata di quella route.
Spiegazione pulita. Ha senso. Quindi ho testato.
Il primo test: niente
Quattro richieste curl contro dot2.solutions/about — tre User-Agent di bot AI e un browser di controllo:
| User-Agent | HTTP | Content-Type | Byte |
|---|---|---|---|
| Browser normale | 200 | text/html | 14052 |
| GPTBot | 200 | text/html | 14052 |
| ClaudeBot | 200 | text/html | 14052 |
| PerplexityBot | 200 | text/html | 14052 |
Risposte identiche. Stesso status, stesso content-type, stesso numero di byte, stessa shell SPA. Nessuna variante markdown. Nessun contenuto diverso per i bot.
Stavo quasi per scrivere quel post. « Lovable l'ha annunciato, ho testato subito, nulla di diverso sul filo. » Dati puliti, conclusione deludente. Posizione scettica facile.
Poi ho fatto un altro test.
Il secondo test: un altro tipo di negoziazione
L'annuncio usava due espressioni distinte: « pre-rendering per le app esistenti » e « output markdown strutturato ». Due feature diverse. La maggior parte degli strumenti di discoverability instrada per User-Agent. Ma « output markdown strutturato » suonava più come HTTP content negotiation — l'approccio standard in cui il client dice al server quale formato vuole, e il server sceglie la risposta migliore.
Quindi ho chiesto markdown direttamente al server:
curl -H "Accept: text/markdown" https://dot2.solutions/about -iRisposta:
HTTP/2 200
content-type: text/markdown; charset=utf-8
content-length: 7693
vary: AcceptCorpo markdown pulito. Metà delle dimensioni della risposta HTML. Titoli, link, paragrafi — contenuto puro, niente chrome, niente script.
L'header vary: Accept è rivelatore. È il server che dice esplicitamente a cache e client: « servo contenuti diversi in base all'header Accept che mi mandi ». HTTP content negotiation standard, esattamente come il web è stato progettato per questo.
Quindi un percorso funzionava. Il percorso User-Agent no. Stesso sito, stesso edge — risultato diverso. È la domanda a cui non potevo rispondere con curl da solo.
La domanda per cui ho dovuto mandare un'email
Se la feature di pre-rendering era reale e distribuita, perché tutti e quattro gli User-Agent dei crawler restituivano shell SPA identiche? O la feature non era live, o il mio test era sbagliato.
Ho chiesto direttamente a Lovable. Il supporto Lovable ha risposto entro un giorno con la risposta:
I test curl che stai facendo restituiranno sempre la shell SPA, anche se tutto funziona perfettamente. Il pre-rendering su Lovable viene servito solo ai bot che Cloudflare ha verificato (il vero Googlebot, il vero GPTBot, ecc., identificati per IP e firma, non solo per user-agent). Quando imposti una stringa user-agent in curl, stai impersonando un bot ma la richiesta proviene comunque dalla tua macchina, quindi Cloudflare non la classifica come bot verificato e viene restituita la shell SPA. È intenzionale, per prevenire abusi.
Cerchio chiuso. La feature funziona. Curl semplicemente non può innescarla — e non è pensato per farlo.
Cosa sta succedendo davvero
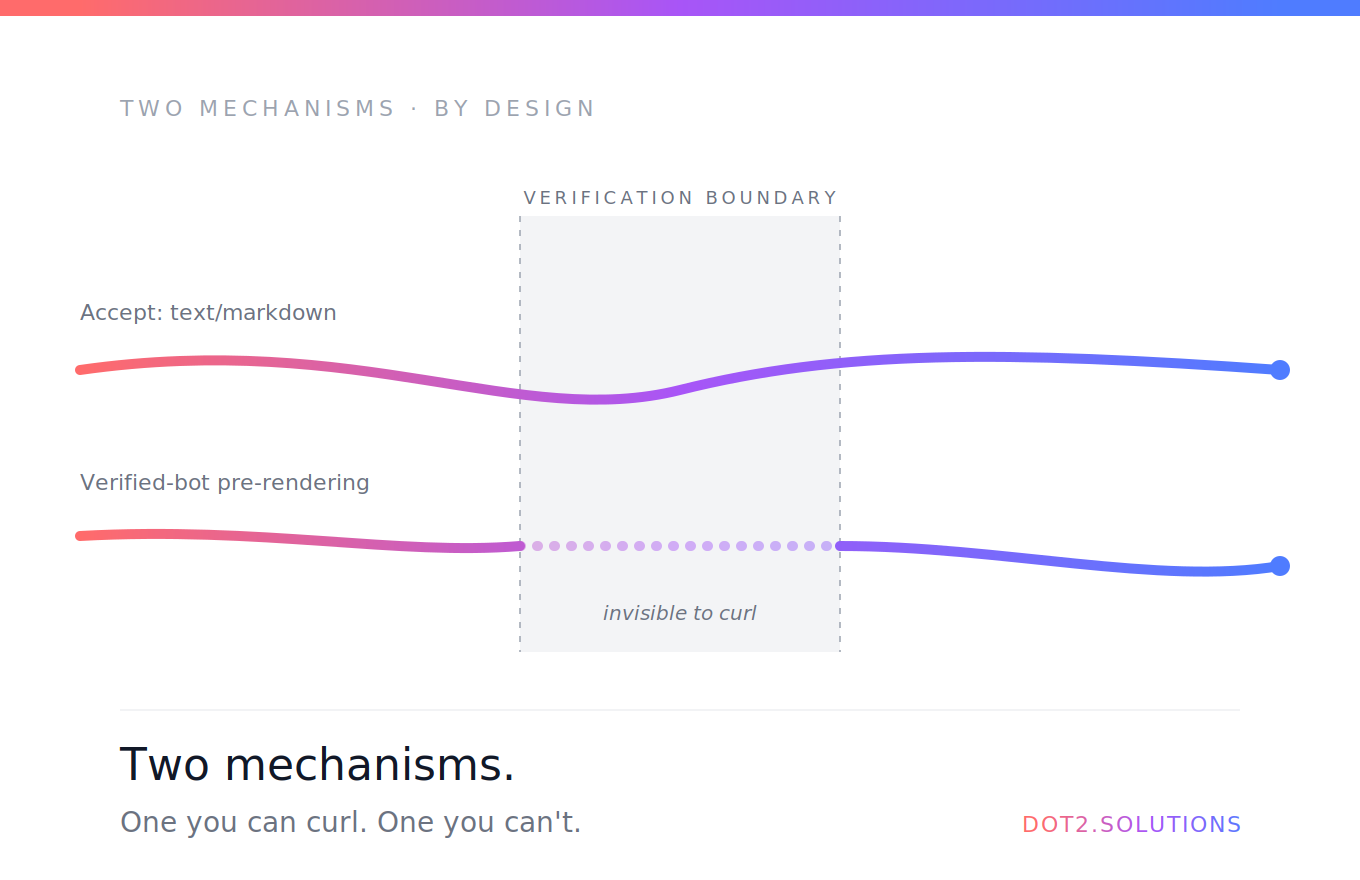
Ci sono due meccanismi che girano in parallelo, ciascuno risolve un problema diverso.
Meccanismo 1: pre-rendering per bot verificati. Quando un vero crawler verificato da Cloudflare colpisce un sito Lovable — Googlebot, GPTBot, ClaudeBot, identificato per IP più firma crittografica anziché per la sola stringa UA — l'edge serve HTML pre-renderizzato. Spoofare lo User-Agent non inganna la verifica Cloudflare, e questo è proprio il punto. Puoi usare qualsiasi UA in curl; Cloudflare sa che la tua richiesta non proviene dall'infrastruttura di OpenAI o Anthropic. Anti-abuso by design.
Meccanismo 2: content negotiation tramite Accept. Qualsiasi client — incluso curl dal tuo laptop — che richiede esplicitamente text/markdown tramite l'header Accept riceve markdown pulito. Nessuna verifica necessaria. È il percorso universale, sempre attivo.
Insieme coprono l'intero panorama del traffico AI:
- I crawler di indicizzazione che si identificano crittograficamente ottengono HTML pre-renderizzato, velocemente.
- Gli strumenti agentici e i fetcher on-demand che richiedono markdown ottengono markdown, indipendentemente da chi sono.
- Tutti gli altri ottengono la normale shell SPA.
È un'architettura intelligente. Anti-spoofing dove lo spoofing conta, content negotiation aperta dove non conta.
Realtà pratica
Il supporto Lovable ha segnalato il limite che altrimenti avrei mancato: in pratica oggi pochissimi assistenti AI richiedono markdown, quindi anche se tutto è collegato correttamente, non vedresti molto traffico reale arrivarci ora.
È vero. Il percorso Accept è compatibile con il futuro — è progettato per gli strumenti AI in arrivo il prossimo anno, non per il panorama bot di oggi. La maggior parte dei crawler AI attuali invia Accept: text/html, */* e riceverà HTML.
Ma l'architettura è posizionata dove sta andando il puck. La lettura URL on-demand di ChatGPT, l'URL fetching di Claude, la modalità ricerca di Perplexity e i framework agentici emergenti richiedono sempre più markdown perché è molto più facile da parsare per un LLM rispetto alla zuppa HTML. Il pre-rendering per bot verificati copre i crawler di indicizzazione adesso. Il percorso Accept copre ciò che viene dopo. L'implementazione è buona per entrambi gli orizzonti temporali.
Metodologia di test, con limiti
Se vuoi verificare la discoverability sul tuo progetto Lovable:
# Ciò che ottengono i browser (e la maggior parte dei crawler attuali)
curl -i https://tuo-dominio.com/una-pagina | head -10
# Ciò che ottiene uno strumento AI che richiede markdown
curl -H "Accept: text/markdown" https://tuo-dominio.com/una-pagina -i | head -10Per la seconda risposta, cerca content-type: text/markdown e un header vary: Accept. Se vedi entrambi, il percorso markdown è attivo sul tuo progetto.
Per il pre-rendering per bot verificati, non puoi testarlo con curl by design. Puoi verificarlo indirettamente tramite lo strumento di ispezione URL di Google Search Console (che ti mostra ciò che il vero Googlebot ha visto durante il suo ultimo crawl) e tramite funzionalità di audit simili in altri strumenti di ricerca AI man mano che diventano disponibili. L'architettura si basa sulla verifica bot di Cloudflare, che è ben documentata e affidabile.
Il pattern
Quando le piattaforme rilasciano feature a meccanismi multipli, gli assistenti AI integrati che spiegano quelle feature tendono a descrivere un meccanismo in modo pulito e a mancare gli altri. Non è cattiveria. È il costo di avere assistenti AI che spiegano feature rilasciate più velocemente di quanto la documentazione riesca a stargli dietro.
Il fix non è diffidare della piattaforma. È testare ciò che si può con curl, sapere cosa curl non può mostrare, e scrivere un'email agli ingegneri quando si tocca il limite.
Per i builder che rilasciano su Lovable: le nuove funzionalità di discoverability sono reali, tecnicamente eccellenti e attive sui progetti esistenti — il mio incluso, anche sul template SPA pre-aprile. Testa il percorso Accept con curl. Fidati del percorso per bot verificati perché è proprio per quello che è progettato. Entrambi fanno lavoro reale.
Per Lovable: l'implementazione è ottima. La spiegazione dell'assistente AI integrato potrebbe coprire entrambi i meccanismi — mi avrebbe risparmiato un paio di giri di curl e un'email. Ma sono contento di aver mandato l'email lo stesso. È così che si impara come funzionano davvero le cose.
In seguito al post SSR della scorsa settimana — questa è la seconda parte di quella che sta diventando una serie sulla storia della discoverability di Lovable. Prossimo episodio: uno sguardo più ravvicinato all'integrazione Semrush e cosa fanno davvero in pratica quei fix SEO in un clic.
Domande frequenti
Hai altre domande?
Share this article
Building on Lovable? Let's Talk.
As a top-ranked Lovable expert, we help teams ship production-grade web apps — SEO, GEO, and SSR done right from day one.
No commitment required • Free 30-minute consultation • Expert guidance
