Eoghan ha detto «Fin per i dentisti». Ha ragione. Ecco cosa significa davvero.
Intercom ha lanciato la Fin API Platform con contratti da 250K$/anno e Apex — un LLM specializzato che supera GPT-5.4 e Opus 4.5. Ma la storia vera non è il modello. È il gap di implementazione verticale.

Chris
April 8, 2026 · 12 min read

Ask AI about this post



La scorsa settimana Intercom ha lanciato la Fin API Platform. I contratti partono da 250K$/anno. Apex — il loro nuovo LLM specializzato per il customer service — secondo i benchmark supera GPT-5.4 e Opus 4.5 su tasso di risoluzione, tasso di allucinazione e latenza.
È un annuncio significativo. E la maggior parte delle analisi si concentrerà sui benchmark del modello.
Io voglio concentrarmi invece su una frase del post di Eoghan McCabe.
«Non costruiremo mai per questi verticali specifici.»
Ecco la citazione completa, sepolta verso la fine del suo annuncio:
«Fin per i dentisti? Perché no. Fin per le concessionarie auto? Certo. Non costruiremo mai per questi verticali specifici, ma ci piacerebbe che lo facesse qualcun altro.»
Rileggi due volte.
Il CEO di Intercom — che annuncia quello che definisce il miglior modello di customer service al mondo — dice apertamente: il lavoro di implementazione verticale non è il nostro.
Non è una frase buttata lì. È un confine strategico. E ha implicazioni reali per chiunque stia implementando Fin con clienti PMI.
Cosa apre davvero la piattaforma API
La Fin API Platform dà ai builder accesso a quattro layer di modello:
- Fin Apex 1.0 — il modello generativo che produce le risposte finali
- Fin RAG API — l'intera pipeline di retrieval-augmented generation
- Fin Retrieval API — un modello di retrieval custom, ottimizzato per il customer service
- Fin Reranker API — scoring di rilevanza per i contenuti recuperati
È infrastruttura davvero potente. I benchmark di Apex sono seri: +2,8% di tasso di risoluzione rispetto ai modelli frontiera, 65% di allucinazioni in meno di Sonnet 4.6, 0,6 secondi più rapido sul time-to-first-token.
L'impatto reale conferma: Intercom ha riferito che un grosso cliente gaming ha visto il proprio tasso di risoluzione passare da un giorno all'altro dal 68% al 75% dopo il rollout di Apex — un calo del 22% delle conversazioni non risolte, e il più grande balzo in singolo step dal lancio di Fin.
Ma il floor annuale di 250K$ dice chiaramente a chi si rivolge la piattaforma: aziende enterprise, startup che costruiscono agenti verticali e concorrenti di piattaforma di Intercom che vogliono licenziare i modelli.
Per la grande maggioranza delle PMI non è terreno di accesso diretto. E va bene così — perché il gap di valore per loro non sta comunque nell'API.
Il layer della conoscenza è ancora il fossato
Ecco cosa ha confermato ogni implementazione AI che ho seguito, e cosa il AI Agent Blueprint di Intercom rende esplicito:
Il tasso di risoluzione non è principalmente un problema di modello. È un problema di contenuto.
Il Blueprint lo dice chiaro: «Gli AI Agent valgono quanto i loro input.» E il commento informale di Eoghan su dentisti e concessionarie punta esattamente alla stessa cosa: puoi avere il miglior modello al mondo, ma se l'architettura della conoscenza sotto non è costruita attorno al funzionamento del tuo verticale, non raggiungerai tassi di risoluzione significativi.
Apex su una knowledge base generica e mal strutturata sotto-performerà. Un'istanza Fin ben configurata su un layer di contenuto pulito e calibrato sul verticale la batterà sistematicamente.
È il gap che la piattaforma API non chiude. Ed è il gap che conta per i deployment PMI. Se stai costruendo o auditando il tuo layer di contenuto, la nostra guida sulle knowledge base per il supporto AI ne copre i principi fondamentali.
Cosa significa in pratica «contenuto prima della configurazione»
Quando in dot2.solutions parliamo di contenuto prima della configurazione, intendiamo qualcosa di specifico:
Prima di toccare una singola impostazione Intercom, devi sapere:
- Quali domande pongono davvero i tuoi clienti (non quelle che pensi pongano)
- Quali sono ad alto volume e bassa complessità — la tua via veloce alla risoluzione
- Dove il contenuto esistente è sbagliato, obsoleto o del tutto mancante
- Come i tuoi SOP si mappano sul formato Procedures di Fin
- Quale logica condizionale richiedono davvero i tuoi workflow più complessi
Questa è l'architettura della conoscenza. Non è glamour. Non fa belle slide di benchmark. Ma è il lavoro che determina se arrivi al 65% di risoluzione o al 30%.
Intercom ha costruito il miglior modello per questo. Ha anche costruito un tooling solido attorno — Guidance, Procedures, Simulations, Topics Explorer. La piattaforma è davvero eccellente. E con il recente lancio di Monitors, anche il layer di observability è ora completo — il che significa che puoi finalmente misurare se le risposte di Fin sono al tuo standard, non solo se risolvono conversazioni.
Quello che non fanno — per loro stessa ammissione — è il lavoro verticale sul contenuto. L'analisi profonda di come una fiduciaria svizzera parla di IVA con i clienti, o di come una SaaS ginevrina gestisce conversazioni di churn in francese. Quello è lavoro di implementazione. È lavoro da practitioner.
L'opportunità che questo crea
La Fin API Platform genererà un'ondata di nuovi builder di agenti verticali. Eoghan li invita esplicitamente. Alcuni saranno startup ben finanziate. Altri società di consulenza che si rebrandizzano dall'oggi al domani.
La maggior parte partirà dal layer modello, perché è ciò che è nuovo ed eccitante.
Quelli che avranno successo finiranno per imparare ciò che ogni implementer Fin esperto sa già: il modello è la parte facile. Ciò che richiede tempo, giudizio e conoscenza di dominio è l'architettura del contenuto sotto.
È l'opportunità asimmetrica per i partner di implementazione che hanno già fatto questo lavoro — che hanno costruito i framework, condotto gli audit di conoscenza e imparato da quali strutture di contenuto Fin risolve davvero e quali invece elude.
Il layer modello si apre. Il layer conoscenza resta il fossato.
Per una visione più ampia di come le strategie di supporto AI proattivo si compongono su questa base, vedi il nostro pezzo sul supporto AI proattivo nel 2026.
Una nota sui benchmark
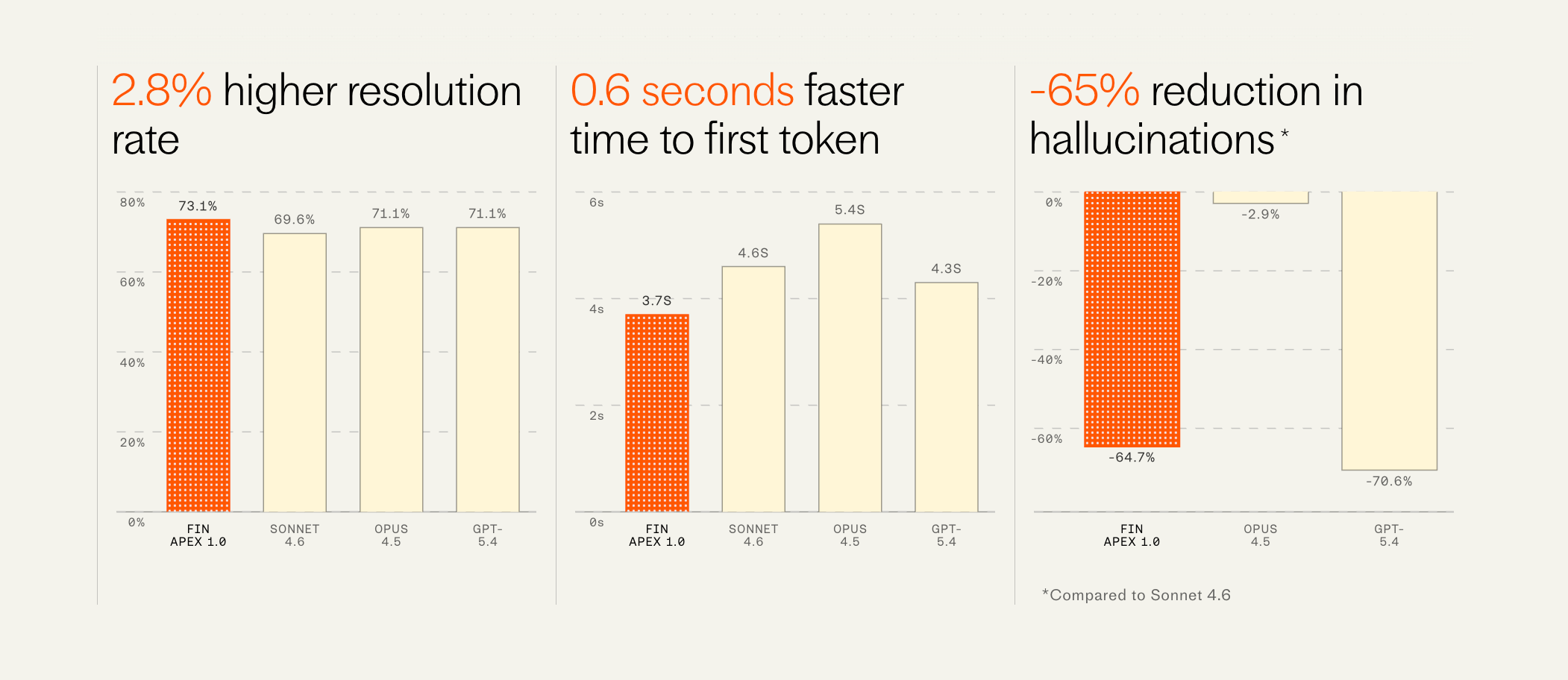
I numeri di Apex meritano un momento. Confrontarsi favorevolmente con GPT-5.4 e Opus 4.5 su un benchmark specifico per il customer service non è un'affermazione banale. Intercom ha un team AI di 60 persone, un decennio di dati di customer service e anni di segnale di produzione da milioni di conversazioni Fin a settimana.
Vedere modelli verticali specializzati superare modelli frontiera generalisti è esattamente ciò che ci si aspetta nei verticali AI maturi. Medico, legale, finanziario e customer service si stanno muovendo tutti in questa direzione. La suite di modelli Fin è avanti rispetto a dove me l'aspettavo.
Il solo Fin Escalation Router — >98% di accuratezza sulle decisioni di handoff, 0,5s più veloce del routing basato su LLM — mostra quanto valore composto si trovi nell'architettura dei sub-agenti specializzati piuttosto che nell'LLM in copertina.
Oltre alla pura performance del modello, la suite completa di Intercom include ora sette modelli specializzati: Apex 1.0, Retrieval, Reranker, Issue Summarizer, Feedback Parser, Language Detector e l'Escalation Router. Ciascuno è costruito e fine-tunato per uno stadio specifico della pipeline di supporto — un'architettura composita difficile da replicare con i soli modelli frontiera generici.
Cosa significa per i nostri clienti
Per le PMI svizzere che implementano Fin tramite dot2.solutions, nel nostro approccio di fondo non cambia nulla. La piattaforma su cui giri è semplicemente diventata sensibilmente migliore. Mentre la piattaforma API custom ha un biglietto d'ingresso da un quarto di milione, Intercom sta integrando il modello Apex direttamente nel prodotto Fin standard. Significa che da ora Apex è il modello dietro la tua istanza Fin.
Cosa migliora: accuratezza di risoluzione, tasso di allucinazione, latenza di risposta e decisioni di escalation.
Cosa non cambia: la qualità della tua knowledge base, la struttura delle tue Procedures, la chiarezza della tua configurazione Guidance. Restano le leve principali per migliorare il tasso di risoluzione — ed è lì che passiamo più tempo.
Se usi già Fin, è un buon momento per rivedere se il tuo layer di contenuto sta tenendo il passo dei miglioramenti del modello. Le strategie su quick questions e risoluzione che abbiamo delineato sono un buon punto di partenza pratico.
Se non usi ancora Fin e questo annuncio ti incuriosisce: il miglior punto di partenza resta un audit della conoscenza, non una valutazione di tool.
Contenuto prima della configurazione. È lì che il tuo tasso di risoluzione si vince o si perde — a prescindere da quanto diventi bravo il modello. Se sei pronto a smettere di mettere mano alle impostazioni e a costruire un layer di conoscenza che risolve davvero i ticket, parliamo di un audit della conoscenza.
Domande frequenti
Hai altre domande?
Share this article
Need Help with Intercom & Fin?
As an Intercom Silver Partner, we specialise in Fin deployment, knowledge base architecture, and AI support automation for Swiss SMEs.
No commitment required • Free 30-minute consultation • Expert guidance


