Lovables neues SEO-Feature, auf zwei Arten getestet — und der Teil, den curl nicht sieht
Ich hätte fast einen anderen Beitrag geschrieben. Curl behauptete, Lovables neue Discoverability-Suite tue nichts. Ein zweiter Test — und eine E-Mail an den Lovable-Support — zeigte zwei Mechanismen, die nebeneinander laufen, und warum einer davon by design unsichtbar ist.

Chris
May 19, 2026 · 7 min read
Ask AI about this post



Gestern hätte ich fast einen anderen Beitrag geschrieben.
Lovable hat eine komplette Discoverability-Suite ausgeliefert — serverseitiges Rendering für neue Apps, Pre-Rendering für bestehende, strukturierte Markdown-Ausgabe für KI-Crawler, Semrush-Integration im Builder-Chat und ein On-Demand-SEO-Review mit Ein-Klick-Fixes. Der Pitch: „Deine Apps sind ab dem Moment der Veröffentlichung auffindbar."
Also habe ich Lovables In-Product-KI-Assistenten gefragt, wie das Feature funktioniert. Er erklärte:
Lovables Hosting-Layer erkennt KI-Crawler (GPTBot, PerplexityBot, ClaudeBot etc.) am User-Agent-Header. Fordert einer dieser Bots eine Seite deiner veröffentlichten Site an, liefert die Edge statt der normalen index.html (einer fast leeren SPA-Shell, die JavaScript zum Rendern braucht) eine pre-renderte Markdown-Version dieser Route aus.
Saubere Erklärung. Ergibt Sinn. Also habe ich getestet.
Der erste Test: nichts
Vier curl-Anfragen gegen dot2.solutions/about — drei KI-Bot-User-Agents und ein Browser als Kontrolle:
| User-Agent | HTTP | Content-Type | Bytes |
|---|---|---|---|
| Normaler Browser | 200 | text/html | 14052 |
| GPTBot | 200 | text/html | 14052 |
| ClaudeBot | 200 | text/html | 14052 |
| PerplexityBot | 200 | text/html | 14052 |
Identische Antworten. Gleicher Status, gleicher Content-Type, gleiche Byte-Zahl, gleiche SPA-Shell. Keine Markdown-Variante. Kein anderer Inhalt für Bots.
Den Beitrag hätte ich fast geschrieben. „Lovable hat es angekündigt, ich habe sofort getestet, auf der Leitung nichts anders." Saubere Daten, enttäuschendes Fazit. Sichere skeptische Haltung.
Dann habe ich noch einen Test gemacht.
Der zweite Test: eine andere Art von Verhandlung
Die Ankündigung verwendete zwei verschiedene Formulierungen: „Pre-Rendering für bestehende Apps" und „strukturierte Markdown-Ausgabe". Zwei verschiedene Features. Die meisten Discoverability-Tools routen per User-Agent. Aber „strukturierte Markdown-Ausgabe" klang eher nach HTTP-Content-Negotiation — dem standardkonformen Ansatz, bei dem der Client dem Server sagt, welches Format er möchte, und der Server die beste Antwort wählt.
Also habe ich den Server direkt nach Markdown gefragt:
curl -H "Accept: text/markdown" https://dot2.solutions/about -iAntwort:
HTTP/2 200
content-type: text/markdown; charset=utf-8
content-length: 7693
vary: AcceptSauberer Markdown-Body. Halb so gross wie die HTML-Antwort. Überschriften, Links, Absätze — purer Inhalt, kein Chrome, keine Skripte.
Der vary: Accept-Header ist der entscheidende Hinweis. Es ist der Server, der Caches und Clients explizit sagt: „Ich liefere unterschiedlichen Inhalt je nach Accept-Header, den ihr sendet." Standardkonforme HTTP-Content-Negotiation, genau so wie das Web dafür gedacht war.
Also funktionierte ein Pfad. Der User-Agent-Pfad nicht. Gleiche Site, gleiche Edge — anderes Ergebnis. Das ist die Frage, die ich mit curl allein nicht beantworten konnte.
Die Frage, für die ich eine E-Mail schreiben musste
Wenn das Pre-Rendering-Feature real und deployed war, warum gaben dann alle vier Crawler-User-Agents identische SPA-Shells zurück? Entweder war das Feature nicht live, oder mein Test war falsch.
Ich habe Lovable direkt gefragt. Der Lovable-Support antwortete innerhalb eines Tages mit der Antwort:
Die curl-Tests, die du machst, geben immer die SPA-Shell zurück, selbst wenn alles perfekt funktioniert. Pre-Rendering auf Lovable wird nur an Bots ausgeliefert, die Cloudflare verifiziert hat (der echte Googlebot, der echte GPTBot etc., identifiziert per IP und Signatur, nicht nur per User-Agent). Wenn du in curl einen User-Agent-String setzt, imitierst du einen Bot, aber die Anfrage kommt trotzdem von deiner eigenen Maschine, also stuft Cloudflare sie nicht als verifizierten Bot ein und die SPA-Shell wird zurückgegeben. Das ist by design, um Missbrauch zu verhindern.
Damit war die Schleife geschlossen. Das Feature funktioniert. Curl kann es nur nicht auslösen — und soll es auch nicht können.
Was tatsächlich passiert
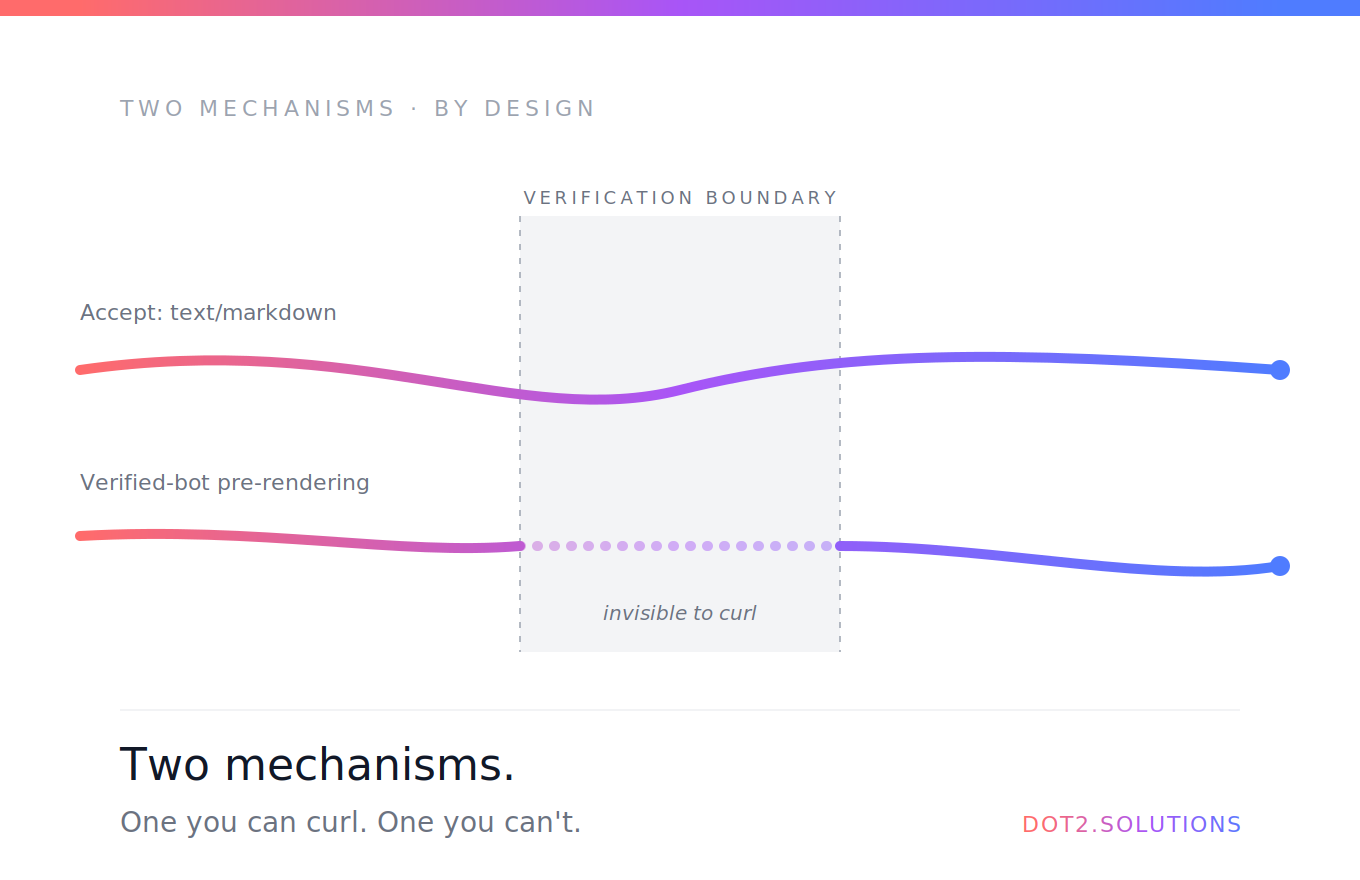
Es laufen zwei Mechanismen nebeneinander, jeder löst ein anderes Problem.
Mechanismus 1: Pre-Rendering für verifizierte Bots. Wenn ein echter, von Cloudflare verifizierter Crawler eine Lovable-Site trifft — Googlebot, GPTBot, ClaudeBot, identifiziert per IP plus kryptografischer Signatur statt nur per UA-String — liefert die Edge pre-rendertes HTML aus. Den User-Agent zu fälschen, täuscht Cloudflares Verifizierung nicht, und genau das ist der Sinn. Du kannst mit jedem beliebigen UA curlen; Cloudflare weiss, dass deine Anfrage nicht aus der Infrastruktur von OpenAI oder Anthropic stammt. Anti-Missbrauch by design.
Mechanismus 2: Accept-Header-Content-Negotiation. Jeder Client — einschliesslich curl von deinem Laptop — der explizit text/markdown per Accept-Header anfordert, bekommt sauberes Markdown zurück. Keine Verifizierung nötig. Das ist der universelle, immer aktive Pfad.
Zusammen decken sie die gesamte KI-Traffic-Landschaft ab:
- Indexing-Crawler, die sich kryptografisch identifizieren, bekommen pre-rendertes HTML, schnell.
- Agentische Tools und On-Demand-Fetcher, die Markdown anfordern, bekommen Markdown, egal wer sie sind.
- Alle anderen bekommen die normale SPA-Shell.
Das ist eine kluge Architektur. Anti-Spoofing, wo Spoofing zählt, offene Content-Negotiation, wo es das nicht tut.
Praktische Realität
Der Lovable-Support hat die Einschränkung benannt, die ich sonst übersehen hätte: in der Praxis fordern heute sehr wenige KI-Assistenten Markdown an, also würdest du selbst bei korrekter Verdrahtung noch nicht viel echten Traffic darauf sehen.
Stimmt. Der Accept-Header-Pfad ist vorwärtskompatibel — er ist für die KI-Tools des nächsten Jahres gedacht, nicht für die heutige Bot-Landschaft. Die meisten aktuellen KI-Crawler senden Accept: text/html, */* und erhalten HTML.
Aber die Architektur ist da positioniert, wohin der Puck unterwegs ist. ChatGPTs On-Demand-URL-Reading, Claudes URL-Fetching, Perplexitys Research-Modus und aufkommende agentische Frameworks fordern zunehmend Markdown an, weil es für ein LLM deutlich einfacher zu parsen ist als HTML-Suppe. Das Pre-Rendering für verifizierte Bots deckt die Indexing-Crawler von heute ab. Der Accept-Header-Pfad deckt das ab, was als nächstes kommt. Die Implementierung ist gut für beide Zeitrahmen.
Testmethodik, mit Grenzen
Wenn du Discoverability auf deinem eigenen Lovable-Projekt verifizieren willst:
# Was Browser (und die meisten heutigen Crawler) bekommen
curl -i https://deine-domain.com/eine-seite | head -10
# Was ein KI-Tool bekommt, das Markdown anfordert
curl -H "Accept: text/markdown" https://deine-domain.com/eine-seite -i | head -10Für die zweite Antwort achte auf content-type: text/markdown und einen vary: Accept-Header. Siehst du beides, ist der Markdown-Pfad in deinem Projekt aktiv.
Das Pre-Rendering für verifizierte Bots lässt sich by design nicht mit curl testen. Du kannst es indirekt über das URL-Inspection-Tool der Google Search Console verifizieren (das dir zeigt, was der echte Googlebot beim letzten Crawl gesehen hat) und über ähnliche Audit-Features in anderen KI-Such-Tools, sobald sie verfügbar werden. Die Architektur stützt sich auf Cloudflares Bot-Verifizierung, die gut dokumentiert und zuverlässig ist.
Das Muster
Wenn Plattformen Features mit mehreren Mechanismen ausliefern, neigen die In-Product-KI-Assistenten, die diese Features erklären, dazu, einen Mechanismus sauber zu beschreiben und die anderen zu übersehen. Das ist keine böse Absicht. Es ist der Preis dafür, dass KI-Assistenten ausgelieferte Features schneller erklären, als die Dokumentation hinterherkommt.
Der Fix ist nicht, der Plattform zu misstrauen. Es ist, mit curl zu testen, was geht, zu wissen, was curl nicht zeigen kann, und den Engineers eine E-Mail zu schreiben, wenn du an die Grenze stösst.
Für Builder, die auf Lovable ausliefern: Die neuen Discoverability-Features sind real, technisch exzellent und auf bestehenden Projekten aktiv — meines eingeschlossen, sogar auf dem Pre-April-SPA-Template. Teste den Accept-Header-Pfad mit curl. Vertraue dem Pfad für verifizierte Bots, weil er genau dafür gemacht ist. Beide leisten echte Arbeit.
Für Lovable: Die Implementierung ist grossartig. Die Erklärung durch den In-Product-KI-Assistenten könnte beide Mechanismen abdecken — das hätte mir ein paar curl-Runden und eine E-Mail erspart. Aber ich bin froh, die E-Mail trotzdem geschickt zu haben. So lernt man, wie die Dinge tatsächlich funktionieren.
Im Anschluss an den SSR-Beitrag von letzter Woche — dies ist Teil zwei einer entstehenden Serie über Lovables Discoverability-Story. Als nächstes: ein genauerer Blick auf die Semrush-Integration und was diese Ein-Klick-SEO-Fixes in der Praxis tatsächlich tun.
Häufig gestellte Fragen
Noch Fragen?
Share this article
Building on Lovable? Let's Talk.
As a top-ranked Lovable expert, we help teams ship production-grade web apps — SEO, GEO, and SSR done right from day one.
No commitment required • Free 30-minute consultation • Expert guidance
