Lovable's New SEO Feature, Tested Two Ways — and the Part Curl Can't See
I almost wrote a different post. Curl said Lovable's new discoverability suite did nothing. A second test — and an email to Lovable support — showed two mechanisms running side by side, and why one of them is invisible by design.

Chris
May 19, 2026 · 7 min read
Ask AI about this post



I almost wrote a different post yesterday.
Lovable shipped a full discoverability suite — server-side rendering for new apps, pre-rendering for existing ones, structured markdown output for AI crawlers, Semrush integration in the builder chat, and an on-demand SEO review with one-click fixes. The headline pitch: "your apps are discoverable the moment you publish."
So I asked Lovable's in-product AI assistant how the feature works. It explained:
Lovable's hosting layer detects AI crawlers (GPTBot, PerplexityBot, ClaudeBot, etc.) by their User-Agent header. When one of those bots requests a page on your published site, instead of returning the normal index.html (a near-empty SPA shell that needs JavaScript to render), the edge serves a pre-rendered Markdown version of that route.
Clean explanation. Made sense. So I tested it.
The first test: nothing
Four curl requests against dot2.solutions/about — three AI bot User-Agents and a browser as control:
| User-Agent | HTTP | Content-Type | Bytes |
|---|---|---|---|
| Regular browser | 200 | text/html | 14052 |
| GPTBot | 200 | text/html | 14052 |
| ClaudeBot | 200 | text/html | 14052 |
| PerplexityBot | 200 | text/html | 14052 |
Identical responses. Same status, same content-type, same byte count, same SPA shell. No markdown variant. No different content for bots.
I almost wrote that post. "Lovable announced it, tested immediately, nothing different on the wire." Clean data, disappointing conclusion. Safe skeptical take.
Then I ran one more test.
The second test: a different kind of negotiation
The announcement had used two distinct phrases: "pre-rendering for existing apps" and "structured markdown output." Two different features. Most discoverability tools route by User-Agent. But "structured markdown output" sounded more like HTTP content negotiation — the standards-compliant approach where the client tells the server what format it wants, and the server picks the best response.
So I asked the server for markdown directly:
curl -H "Accept: text/markdown" https://dot2.solutions/about -iResponse:
HTTP/2 200
content-type: text/markdown; charset=utf-8
content-length: 7693
vary: AcceptClean markdown body. Half the size of the HTML response. Headers, links, paragraphs — pure content, no chrome, no scripts.
The vary: Accept header is the giveaway. It's the server explicitly telling caches and clients: "I serve different content based on the Accept header you send." Standards-compliant HTTP content negotiation, exactly the way the web was designed for this.
So one path worked. The User-Agent path didn't. Same site, same edge — different outcome. That's the question I couldn't answer with curl alone.
The question I had to email about
If the pre-rendering feature was real and deployed, why did all four crawler User-Agents return identical SPA shells? Either the feature wasn't live, or my test was wrong.
I asked Lovable directly. Lovable support replied within a day with the answer:
The curl tests you're running will always return the SPA shell, even if everything is working perfectly. Prerendering on Lovable is only served to bots that Cloudflare has verified (the real Googlebot, the real GPTBot, etc., identified by IP and signature, not just user-agent). When you set a user-agent string in curl, you're impersonating a bot but the request still comes from your own machine, so Cloudflare doesn't classify it as a verified bot and the SPA shell is what gets returned. This is by design, to prevent abuse.
That closed the loop. The feature works. Curl just can't trigger it — and isn't supposed to be able to.
What's actually happening
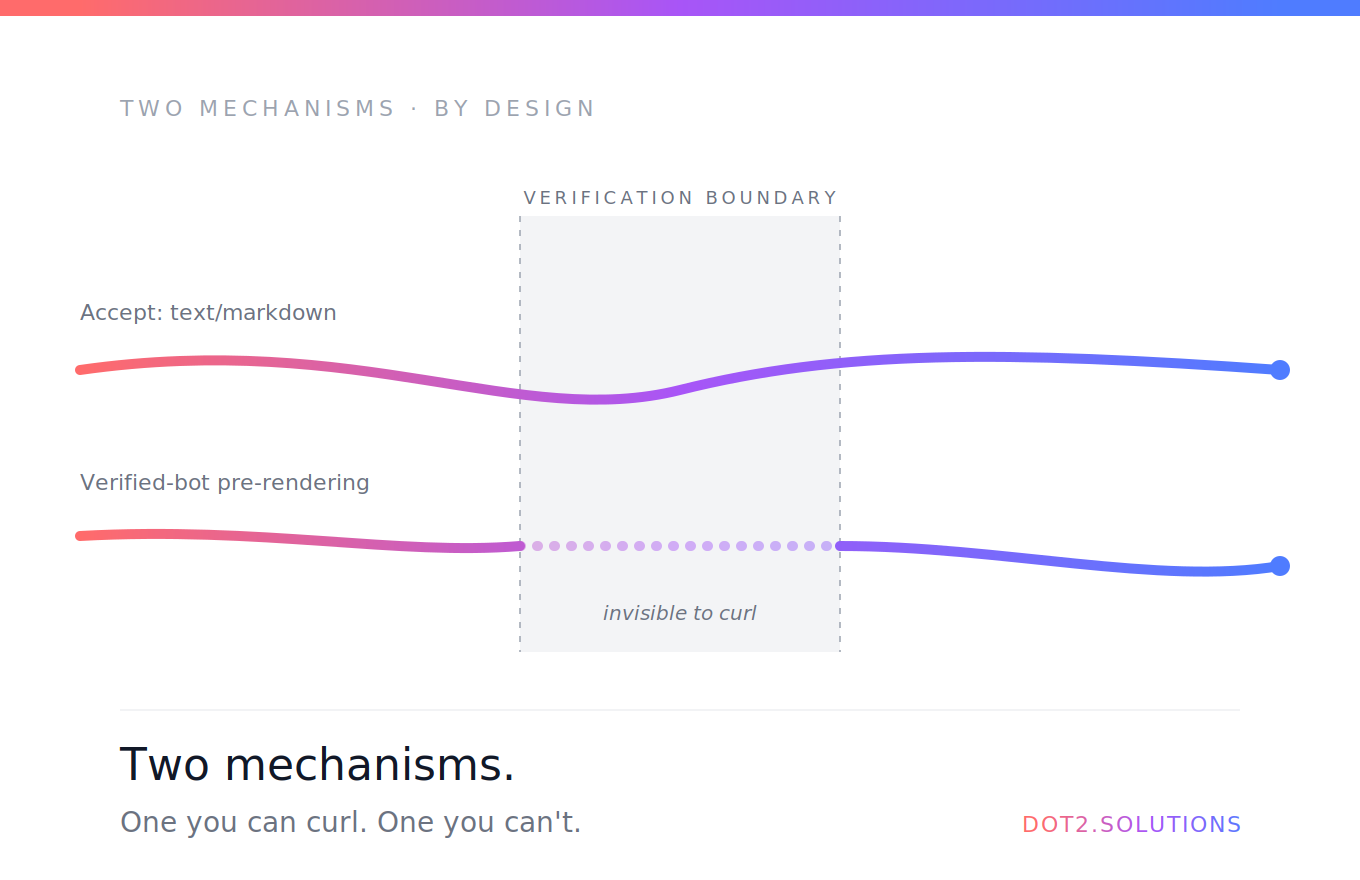
There are two mechanisms running side by side, each solving a different problem.
Mechanism 1: verified-bot pre-rendering. When a real Cloudflare-verified crawler hits a Lovable site — Googlebot, GPTBot, ClaudeBot, identified by IP plus cryptographic signature rather than just the UA string — the edge serves pre-rendered HTML. Spoofing the User-Agent doesn't fool Cloudflare's verification, which is the whole point. You can curl with any UA you want; Cloudflare knows your request didn't originate from OpenAI's or Anthropic's infrastructure. Anti-abuse by design.
Mechanism 2: Accept-header content negotiation. Any client — including curl from your laptop — that explicitly requests text/markdown via the Accept header gets clean markdown back. No verification needed. This is the universal, always-on path.
Together, they cover the full AI traffic landscape:
- Indexing crawlers that identify themselves cryptographically get pre-rendered HTML, fast.
- Agentic tools and on-demand fetchers that request markdown get markdown, regardless of who they are.
- Everyone else gets the normal SPA shell.
That's a smart architecture. Anti-spoofing where spoofing matters, open content negotiation where it doesn't.
Practical reality
Lovable support flagged the limitation I would have missed otherwise: very few AI assistants are actually requesting markdown today in practice, so even if it's wired up correctly, you wouldn't see much real-world traffic hit it yet.
That's right. The Accept-header path is forward-compatible — it's designed for the AI tools coming next year, not the bot landscape today. Most current AI crawlers send Accept: text/html, */* and will receive HTML.
But the architecture is positioned where the puck is going. ChatGPT's on-demand URL reading, Claude's URL fetching, Perplexity's research mode, and emerging agentic frameworks increasingly request markdown because it's dramatically easier for an LLM to parse than HTML soup. The verified-bot pre-rendering covers indexing crawlers right now. The Accept-header path covers what's coming next. The implementation is good for both timeframes.
Test methodology, with limits
If you want to verify discoverability on your own Lovable project:
# What browsers (and most current crawlers) get
curl -i https://your-domain.com/some-page | head -10
# What an AI tool requesting markdown gets
curl -H "Accept: text/markdown" https://your-domain.com/some-page -i | head -10For the second response, look for content-type: text/markdown and a vary: Accept header. If you see both, the markdown path is active on your project.
For the verified-bot pre-rendering, you can't test it with curl by design. You can verify it indirectly through Google Search Console's URL Inspection tool (which shows you what real Googlebot saw on its last crawl) and through similar audit features in other AI-search tools as they become available. The architecture relies on Cloudflare's bot verification, which is well-documented and reliable.
The pattern
When platforms ship multi-mechanism features, the in-product AI assistants explaining those features tend to describe one mechanism cleanly and miss the others. That's not malice. It's the cost of having AI assistants explain shipping features faster than documentation can catch up.
The fix isn't to distrust the platform. It's to test what you can with curl, know what curl can't show you, and email the engineers when you hit the limit.
For builders shipping on Lovable: the new discoverability features are real, technically excellent, and active on existing projects — mine included, even on the pre-April SPA template. Test the Accept-header path with curl. Trust the verified-bot path because that's what it's designed for. Both are doing real work.
For Lovable: the implementation is great. The in-product AI explanation could cover both mechanisms — would have saved me a couple of curl rounds and an email. But I'm glad I sent the email anyway. That's how you learn how things actually work.
Following up on the SSR post from last week — this is part two of what's becoming a series on Lovable's discoverability story. Next up: a closer look at the Semrush integration and what those one-click SEO fixes actually do in practice.
Frequently asked questions
Still have questions?
Share this article
Building on Lovable? Let's Talk.
As a top-ranked Lovable expert, we help teams ship production-grade web apps — SEO, GEO, and SSR done right from day one.
No commitment required • Free 30-minute consultation • Expert guidance
